题目:Characterizing Microservice Dependency and Performance: Alibaba Trace Analysis
来源:SoCC 2021
作者:中国科学院深圳先进技术研究院, 阿里巴巴
摘要
现在有大量针对微服务架构的研究,比如资源管理、弹性伸缩以及故障诊断等。但是目前仍缺乏针对生产环境中微服务特性的实证研究。这篇文章对阿里巴巴公布的trace数据集1进行了详细的实证分析,从以下角度揭示了生产环境下微服务系统的特点:
- 微服务调用图的特点,与传统作业DAG的不同
- 无状态微服务之间的依赖关系
- 微服务系统的运行时性能受哪些因素的影响
此外,现有的微服务benchmark也存在一些问题,如:
- 规模太小。经典的benchmark(如DeathStarBench2),只包含数个微服务(不超过40)。在这些小规模的微服务benchmark上得到的结论不一定能推广到生产环境中;
- 静态依赖。这些benchmark的依赖关系都是静态的,无法模拟生产环境中常见的动态性。
所以这篇文章还基于阿里巴巴的trace数据构建了一个仿真的数学模型,模拟大规模动态微服务系统。
背景
微服务架构
这里首先介绍了微服务架构的调用图,以及图中常见的组件:
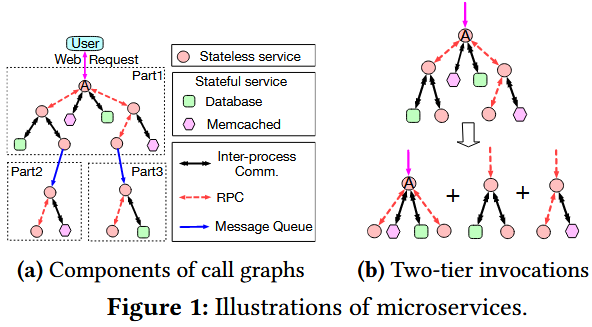
这里引入了几个关键术语:
- Entering Microservice:入口微服务,即请求进入微服务系统的入口。通常是前端微服务。
- UM, DM:分别指代一条调用链路的上游微服务(upstream microservice)和下游微服务(downstream microservice)。
对于微服务种类,文章基于服务提供的功能将微服务划分为有状态微服务(stateful)和无状态微服务(stateless)。
- stateful微服务:通常存储有一些状态数据,常见的有数据库(database)和缓存(memCached),它们大多的接口大多分为两类:reading 和 writing。
- stateless微服务:不存储状态数据,所以可以轻松的伸缩,它们通常提供成百上千个不同接口,用于完成不同的业务功能。
对于微服务交互种类,文章基于交互协议划分了三种类别:
- IP:进程间通信(Inter Process communication),常发生在stateless微服务和stateful微服务之间。
- RPC:远程过程调用(Remote Procedure Call),一种双向通信,DM必须返回给UM结果。
- MQ:消息队列(Message Queue),一种单向通信,UM发送消息到第三方中间件(消息队列),消息队列储存这个消息,直到DM主动取出这个消息。
一般来说,RPC效率高,MQ更加灵活。
此外,还介绍了两个概念:调用深度(call depth)和响应延迟(RT)。
- call depth:调用深度指调用图中最长的路径长度,比如Figure 1中的调用图长度为5。
- RT:从UM发出请求到UM收到回复的时长。即使同一种接口的请求也会因为参数、状态的不同产生差距较大的延时。
Alibaba Trace
alibaba的trace与常见的trace数据模型不同3,因为它更像一种多模态监控数据,包含了节点信息、指标以及调用链等。具体信息如下:
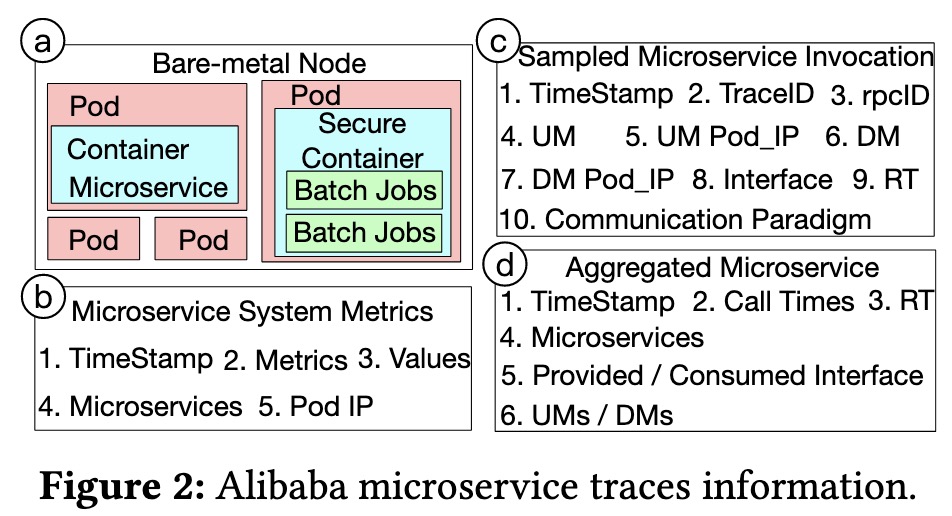
物理运行环境:阿里巴巴的集群采用K8s进行管理,整个集群运行在裸机云(bare-metal cloud)上,服务与作业通常混合部署在一起以提高资源利用率。Figure 2 (a) 介绍了云上两种常见的运行方式:
- Online Services:比如微服务,运行在容器中,直接由K8s管理,有持续向外界提供服务的能力。(stateful微服务一般部署在特定集群中,不参与混合部署)
- Offline Jobs:这些作业一般都需要执行特定的任务,需要K8s事先为它们分配资源,然后调度到特定的机器上执行。
微服务系统指标:这个大概分为三个部分:硬件层(缓存命中率)、操作系统层(CPU利用率)、应用层(JVM垃圾回收),具体内容如Figure 2 (b)。
微服务调用链:如Figure 2 (c)所示,大体上与OpenTracing的数据模型类似,但是摒弃了
spanID和parentSpanId,只留下UM和DM的信息,并用rpcId来唯一标识一个trace内的不同调用,Communication Paradigm代表调用类型(又名rpctype,如rpc)。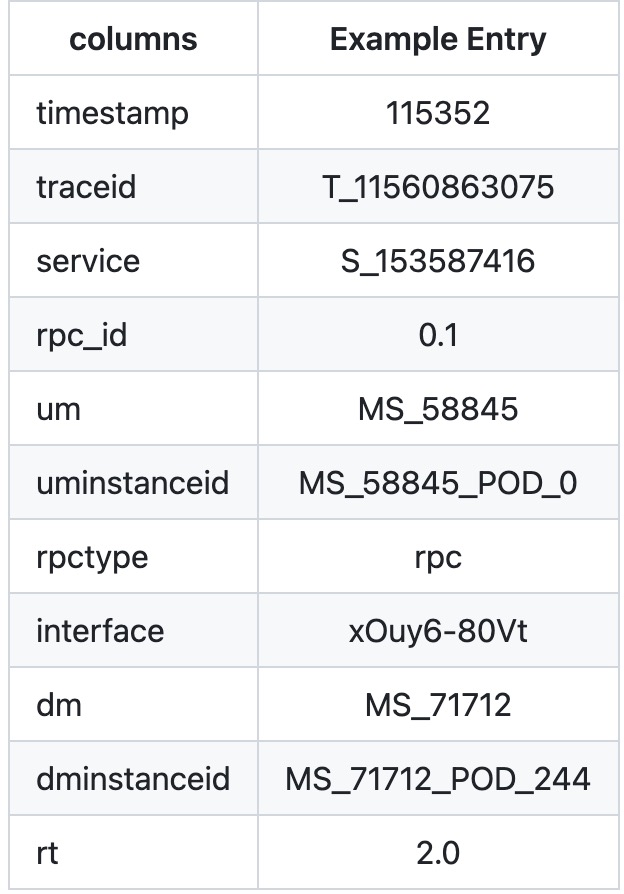
聚合调用:如Figure 2 (d)所示,本质上是对单个微服务的调用信息进行聚合和统计。
调用图的剖析
这一块内容很多,我只提炼出较为有意义的部分。这里的调用图(call graph)并不是指整个微服务依赖图,应该指的是单个trace的拓扑图。
微服务调用图特征
作者在这里总结了三个特征,对下游任务非常有启发:
调用图的微服务数量呈现长尾分布
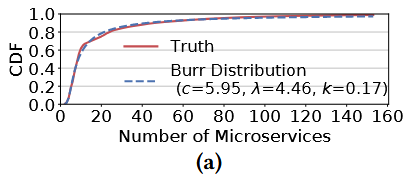
现有的benchmark太小了:10%的调用图的微服务数量>40,存在微服务数量>100的调用图。 大量的Memcacheds:大规模的调用图中有一半的微服务都是Memcacheds,可能是为了减少RT。
调用图是一棵树,并且很多图是一条长链路
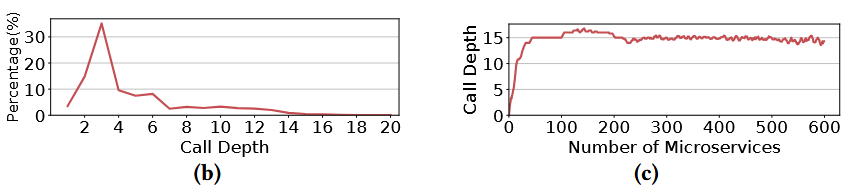
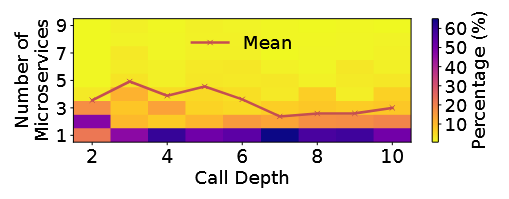
较短的深度:一半的调用图深度在2~4 (a) 树有点胖:,深度随着微服务数量增加没有明显变化 (b),说明调用图是宽且浅的?很多下游微服务只是简单的查询数据(stateful微服务一般是叶子节点) 较深的图一般都是长链路:深度增加,但是后面的的微服务数量大多为1个,说明这棵树的宽度基本集中在第2层,后面的都是一条长链路
有些下游任务(弹性伸缩)会对调用图进行编码,作者特别提到有些图有很长的深度,会让这些任务产生很大的模型以及过拟合。我觉得这没有直接关系,这些数量远远达不到图网络的极限。而且这个实验也可以反过来说,大部分图深度都是很短的。
许多stateless微服务是热点

存在高入度微服务:有5%的stateless微服务入度>16,这些微服务在90%的调用图存在,处理了95%的请求。这些服务很大概率是瓶颈,可以用来指导弹性伸缩。
- 微服务调用图大多是动态的

这个动态和其他文章提到的动态不一样,文中的动态性指的是请求同一个服务的接口,如果参数不一样,会产生不同的拓扑链路(Figure 6);其他文章提到的是微服务系统始终在动态变化。
微服务调用关系特征
不同层之间调用类型差别大
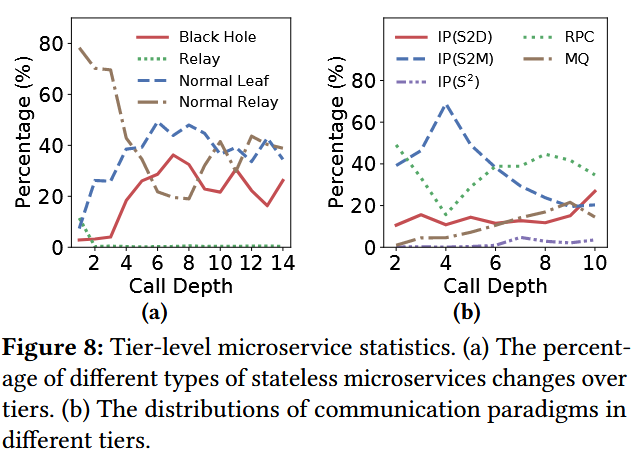
首先考虑微服务是否DM,大致分为以下几类:①
black holes(没有DM),②relay(必须有DM),③normal(一定概率有DM)
IP(S2D),IP(S2M),IP(S2) 表示IP通信的双方分别为:stateless 微服务与database,stateless 微服务与Memcacheds,stateless微服务与stateless微服务
深度增加,black holes比例增加,relay比例减少,normal中对应部分也是如此。
深度增加,IP(S2M) 比例先增后减,IP(S2D)在升高,表明缓存命中率在下降,转而去查询数据库。MQ比例增加,说明业务链路较深时(业务复杂),倾向于使用MQ来减少RT
微服务之间的依赖
这一章节对如何设计和优化微服务架构有启发,不是我研究的范畴,暂时略过
并行依赖
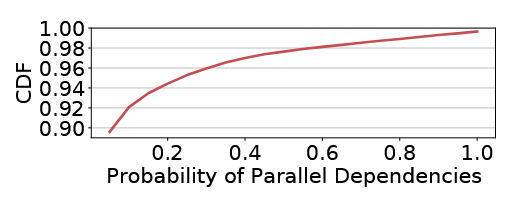
并行依赖很少:数据集中大部分的微服务都很少被并行调用,这个并行给我的感觉就是异步调用
微服务的运行时性能
这个章节很重要,对资源管理有很大的指导作用。首先介绍一个定义:MCR代表微服务调用速率,我的理解是服务承受的负载
MCR对资源的影响
- MCR与CPU利用率和Young GC强相关,但与Memory利用率相关性弱
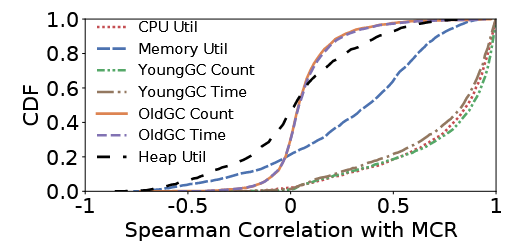
与CPU利用率,Young GC强相关:Young GC指的是对JVM堆内存中的新生代区域进行垃圾回收4,Young GC频繁会造成性能下降或者应用stop,可能是因为内存泄漏等原因。 与内存,Old GC相关性弱:alibaba trace中容器的内存一般都很稳定,Old GC频率可能也是如此(老年代本身垃圾回收就不频繁),所以在实验中不是很明显(受限于数据集特征)。
- 资源对响应时间的影响
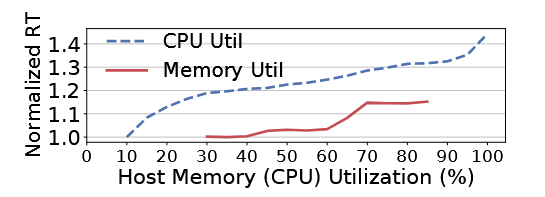
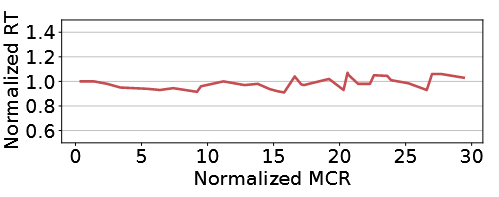
图中的延时选的是P75延时 > 与CPU利用率强相关:随着CPU利用率升高,RT明显升高,但RT对内存反应不是很明显(可能是因为缺乏高内存数据) > 与容器的MCR不太相关:Alibaba trace中即使MCR很高了,CPU利用率可能还低于10%,所以RT变化不大,说明资源浪费很严重
随机图模型

这里简单讲一下,代码实现应该不难: 1.
准备一个存储stateless服务的队列\(Q\),并放入Entering Microservice 2.
执行循环,直到\(Q\)为空 1. \(Q\)弹出一个服务作为UM 2.
如果UM的类型是Relay或者normal (Relay),则根据数据集中DM服务类型的分布,生成对应类型的服务数量
3. 为生成的DMs中不同服务类型确定communication paradigm 4.
将生成的DMs中stateless的微服务放入\(Q\)
3. 图优化 1. 遍历生成的图的每一层 1.
随机选择两个父项,如果他们共享相同的标签,则合并他们的两个孩子。 2.
合并的节点将连接到两个父节点
暂时还没有看到随机模型被其他论文使用,可能是因为大家都可以自己搭建环境生产数据吧,也可能是因为alibaba trace够用了
参考文献
[2] Yu Gan. An Open-Source Benchmark Suite for Microservices and Their Hardware-Software Implications for Cloud & Edge Systems. ASPLOS, 2019. https://github.com/delimitrou/DeathStarBench
[3] OpenTracing, “Opentracing,” https://opentracing.io/specification
[4] java 六 Young GC 和 Full GC https://www.cnblogs.com/klvchen/articles/11758324.html