题目:StatuScale: Status-aware and Elastic Scaling Strategy for Microservice Applications
来源:arxiv 2024
作者:中国科学院深圳先进技术研究院
摘要
相比于单体架构,微服务架构具有更好的弹性,可以进行微服务级别的弹性伸缩。然而,现有的弹性伸缩无法检测突发流量,突发流量可能由很多原因引起:
- 商店促销
- 特殊活动
- 软件故障
- ...
这些突发流量通常是短暂(short-lived)且超出预期的(unexpected),会造成瞬间的性能降级。微服务必须要快速分配足够数量的资源以保证性能。
本文推出了一种状态感知的弹性伸缩控制器
StatusScale,能够感知负载的趋势,预测流量峰值,并进行水平伸缩和垂直伸缩。此外,本文提出了一种新的指标:
correlation factor:评估资源使用的效率
文章在 Sock-Shop 和 Hotel-Reservation 应用上进行评估,将响应延时降低了接近10%,资源利用效率得到提高。
方法
StatuScale
根据当前负载状态选择不同的资源分配方案(垂直和水平),架构如下:
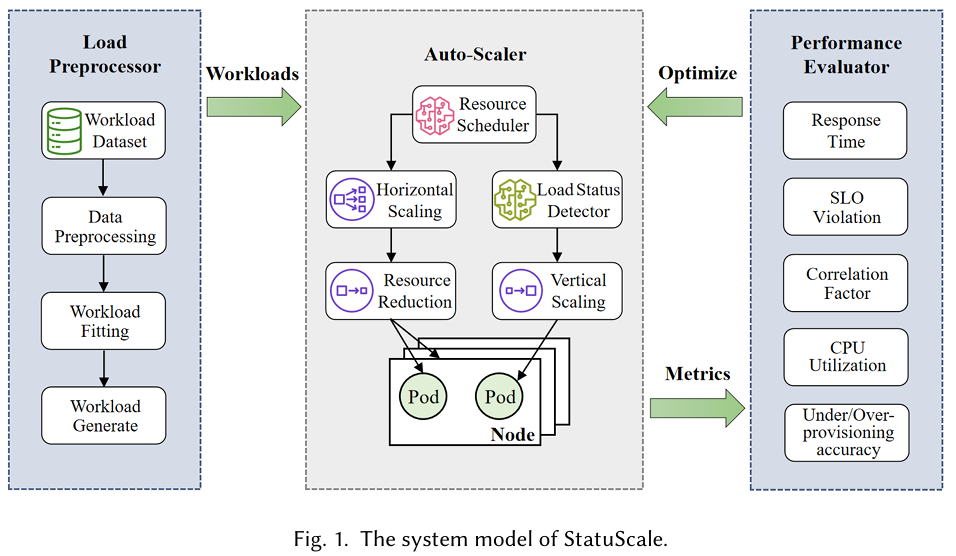
Load Preprocessor是产生流量的模块Auto Scaler是全文核心,分为:- Vertical Scaling:对负载状态进行预测,制定垂直伸缩方案
- Horizontal Scaling:负载状态不稳定时,进行水平伸缩
Performance Evaluator是评估模块,主要评估响应延时、SLO违背率、资源利用效率、资源消耗等
系统建模
弹性伸缩的优化目标和约束如下:
\[ \mathop{\sum_{m\in M}{P_m/A_M \times \sum_{p\in P}{R_p/A_p}+\omega^t\sum_{m\in M}RT_m/A_M}} \]
\[ s.t. \quad P_m \geq 1, \quad R_p, RT_m \geq 0,\quad A_p\geq A_M\geq 0 \]
\(M\) 代表微服务集合,\(A_M\) 代表应用中微服务的数量(即 \(|M|\)),\(P\) 代表应用中pod集合,\(A_p\) 代表应用中pod的数量(即 \(|P|\)),\(P_m\) 代表微服务 \(m\) 的pod数,\(R_p\) 代表为pod \(P\) 垂直分配的资源配额,\(RT_m\) 代表微服务 \(m\) 的响应延时。
优化目标的前半部分是资源消耗(服务的平均pod数\(\times\)pod平均资源额度),后半部分是平均延时,权重设置为 \(\omega^t\)。目标是同时优化资源消耗和响应延时。
垂直伸缩
微服务的负载可能由于特殊的用户活动(e.g., 商品促销)而陡然升高,进而导致服务资源不足而性能下降。所以监控、分析和理解负载的趋势是非常重要的。
基于 LightGBM 的负载预测器
为了能高效地进行负载预测,作者没有采用较重的深度学习或者机器学习模型,而是准备选用基于集成模型的 LightGBM 来进行预测。
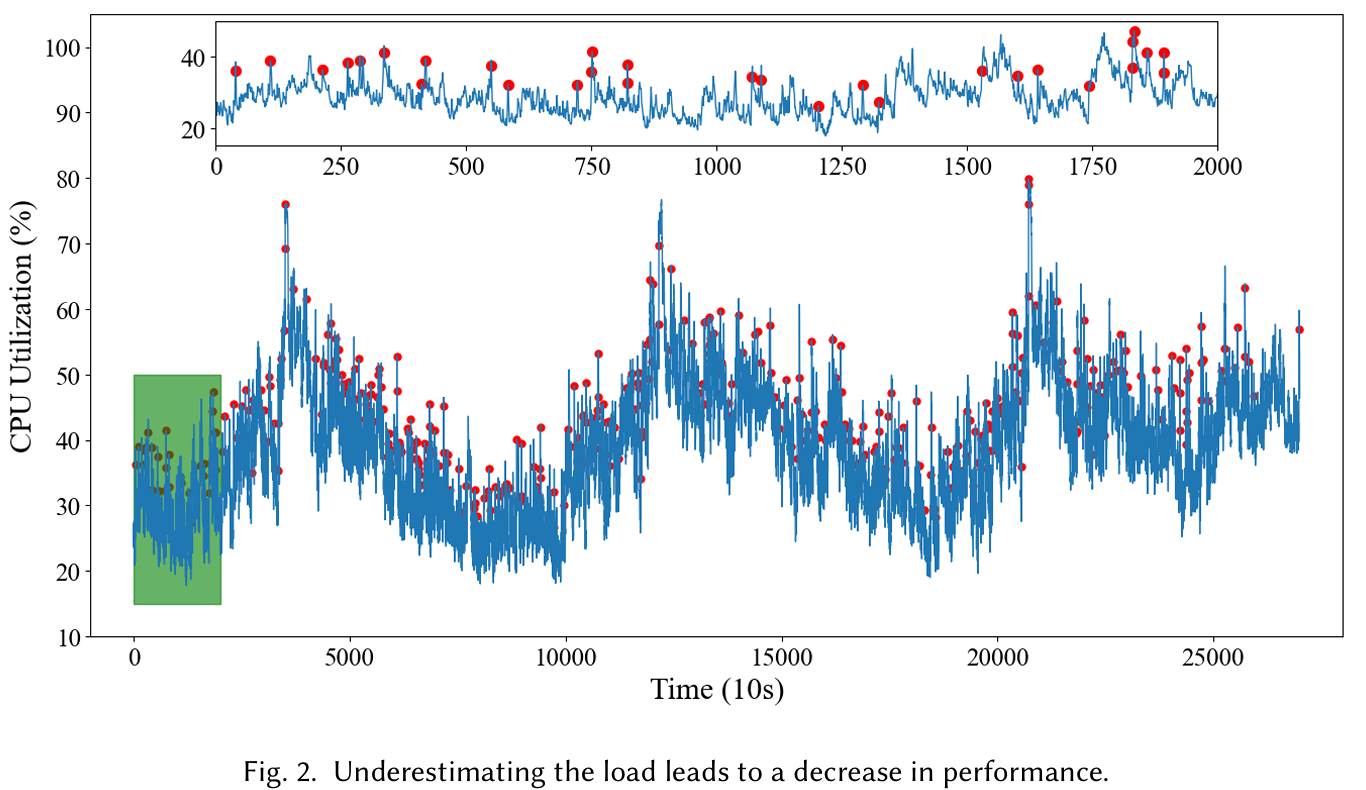
遗憾的是,LightGBM 面临准确性问题,在Fig. 2中,作者试图用 LightGBM 预测 Alibaba 数据集的负载,但是出现了大量负载低估的情况。这些低估会导致资源分配较少,进而导致性能下降。
Load Status Detector
文章另辟蹊径,不再直接训练和预测负载的准确值,而是判断负载是否处于
“stable” 状态。文章引入了金融分析中常用的
resistance line 和 support line
两个概念用来辅助判断。
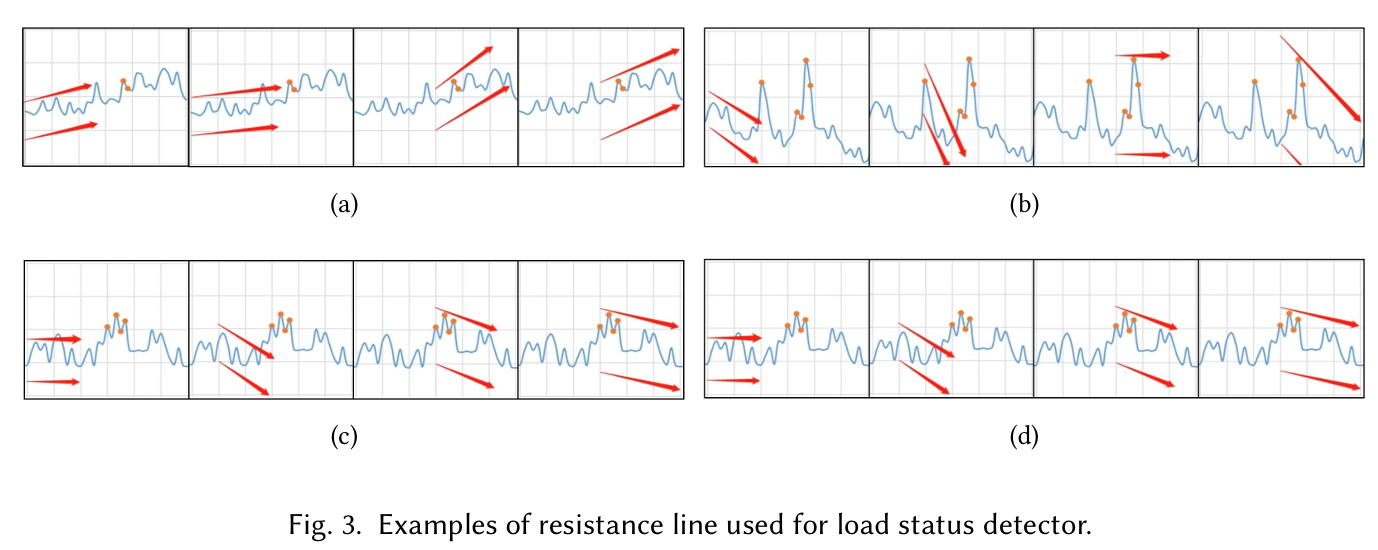
在 Fig. 3 (a)中,作者展示了如何根据 resistance line 和
support line
进行负载状态感知。图中橙色的点是预测时的低估点。首先将x轴分为6个时间窗口,每个时间窗口有5个数据点。
- 首先,
StatuScale使用第1个窗口的数据去生成resistance line和support line - 然后,去判断第2个窗口是否违背了第1个窗口的
resistance line和support line。如果违背了,则判断状态为 “unstable”,采取特定的伸缩策略;如果没有违背,则判断状态为 “stable”,则能够继续进行负载预测。Fig. 3 (a) 中状态为 “stable” - 合并第1个和第2个窗口的数据来更新
resistance line和support line,进而判断第3个窗口超过了resistance line,所以标记第3个窗口状态为 “unstable” - 第4个窗口重新生成
resistance line和support line,重复上述过程
resistance line 和 support line
相当于负载波动的上下边界,在边界内的负载一般都是
“stable” 的。
对于resistance line 和
support line的建模,作者摒弃了复杂的非线性函数,因为担心会导致过拟合。此外,作者又担心线性函数过于简单,所以决定采用分段线性函数(因为分段线性函数可以解决周期负载的判断问题),所以就有了
“unstable” 后进行resistance line 和
support line重置的环节。resistance line的定义如下:
\[ f(t) = kt+b+\lambda c_v \]
\(k\), \(b\)
分别代表斜率和截距,可以通过多项式拟合数据点得到。\(t\) 代表时间。\(c_v\) 代表变异系数(\(\frac{\mu}{\sigma}\)),用来表示样本的分散程度,也为resistance line留有了一定的容错空间。\(\lambda\) 是权重超参数。
自适应PID控制器
在上节中,StatuScale
已经能判断出服务的负载状态,当负载状态为 “unstable”
时,采用 PID
控制器来维持状态的稳定,目标是使得CPU利用率稳定,以及满足SLO。
PID 控制器是广泛使用的控制器,由 1)比例 proportional、 2)积分 integral、 3)导数 derivative 组成。PID 控制器旨在根据feedback更新参数,调整输出,使得状态稳定在目标值附加,输出的分数公式如下:
\[ y(t) = k_Pe(t)+k_I\int_{t-w}^{t}{e(\tau)d\tau+k_D\frac{d}{dt}e(t)} \]
其中,\(e(t)\)代表时刻t的误差(给定值-测量值)。\(k_P\),\(k_I\),\(k_D\) 分别是比例增益(proportional)、积分系数(integral)以及导数系数(derivative),分别代表当前误差,过去一段时间的误差以及预测未来的误差的权重。
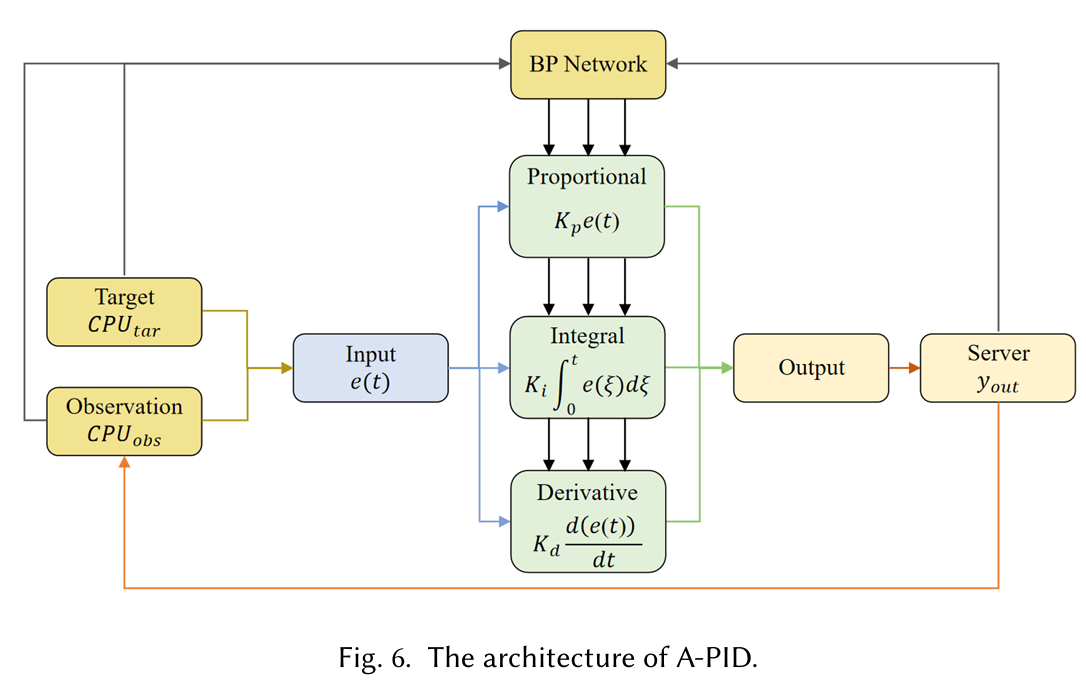
PID 控制器的各项权重 \(k_P\),\(k_I\),\(k_D\)
对系统的稳定性影响很大,StatuScale
引入了一种自适应调节各项权重的 A-PID 控制器。如 Fig.6 所示,A-PID 引入了
BP 网络来调节 PID 的参数(i.e., \(k_P\),\(k_I\),\(k_D\))。BP 网络的配置如下:
- 输入:输出值、目标值、误差、bias
- 中间层:hidden size = 5,激活函数为 tanh
- 输出:\(k_P\),\(k_I\),\(k_D\),激活函数为 sigmoid
这里文章漏掉了最关键的 loss,我只能猜测 loss 的原理是,如果当前误差较大,我们希望新的参数能够更大幅度地改变,以便更快地纠正误差;反之,如果误差较小,则应谨慎调整参数,避免过度校正,所以猜测 loss 为 误差相关的函数。
此外,A-PID的 output 是如何转化为 CPU 的分配?CPU target是多少?垂直伸缩这一块并不是讲的很清楚
水平伸缩
文章认为水平伸缩比垂直伸缩更难,因为水平伸缩需要时间去创建和移除POD,并需要时间去进行负载均衡,同时不必要的水平伸缩操作会导致资源浪费。此处引用了ATOM1的结论:
- 低负载:垂直伸缩更有优势,因为资源分配快
- 高负载:水平伸缩更有优势,因为多个pod分布在多个机器上,将负载均衡了,大大降低了单个pod的压力
所以 StatuScale
会优先考虑垂直伸缩(在低负载下更有优势);如果垂直伸缩无法满足需求,才会考虑用水平伸缩进行粗粒度调整。再用垂直伸缩进行细粒度调整。
首先,StatuScale
将会判断是否需要进行水平伸缩操作,计算当前CPU利用率 \(C_t\) 与目标CPU利用率 \(CPU_{tar}\)
之间的差距,并根据这个差距生成一个转换后的结果 \(S_t\):
\[ S_t = \begin{cases} 1-K^{(CPU_{tar}-C_t)}& C_t < CPU_{tar}\\ K^{C_t-(CPU_{tar})}-1& C_t \geq CPU_{tar} \end{cases} \]
当前CPU利用率 \(C_t\) 接近目标值
\(CPU_{tar}\),\(|S_t|\)接近0;否则,\(|S_t|\)值将以指数倍数增长。StatuScale
统计一段滑动窗口内的不同时间点的 \(S_t\)
的和(减少突发流量的影响),并与上下阈值进行比较,以决定是否进行弹性伸缩。
但是文章并没有给出上下阈值的计算方式?
当决定采用弹性伸缩时,给定当前副本数(\(R_c\)),伸缩比例(\(\delta\)),伸缩的副本数定义如下:
\[ R_n = max(\delta R_c, 1) \]
因为水平伸缩的pod需要一段时间才能生效,所以这段时间可能会频繁触发弹性伸缩,所以
StatuScale 引入了 cooling-off
周期来减少伸缩次数(这段时间不会触发第二次伸缩,默认为5min)
接下来文章用垂直伸缩来进行细粒度资源调整,具体来说,就是通过一个衰减率来周期地减少资源配额,资源值设置如下:
\[ V(t) = Vk^{\beta^t-1} \]
\(0<\beta<1\) 是衰减率,\(V\) 是资源初始值。 > 这里只有减少垂直资源分配,相当于减少水平伸缩多余的那部分资源
联合伸缩
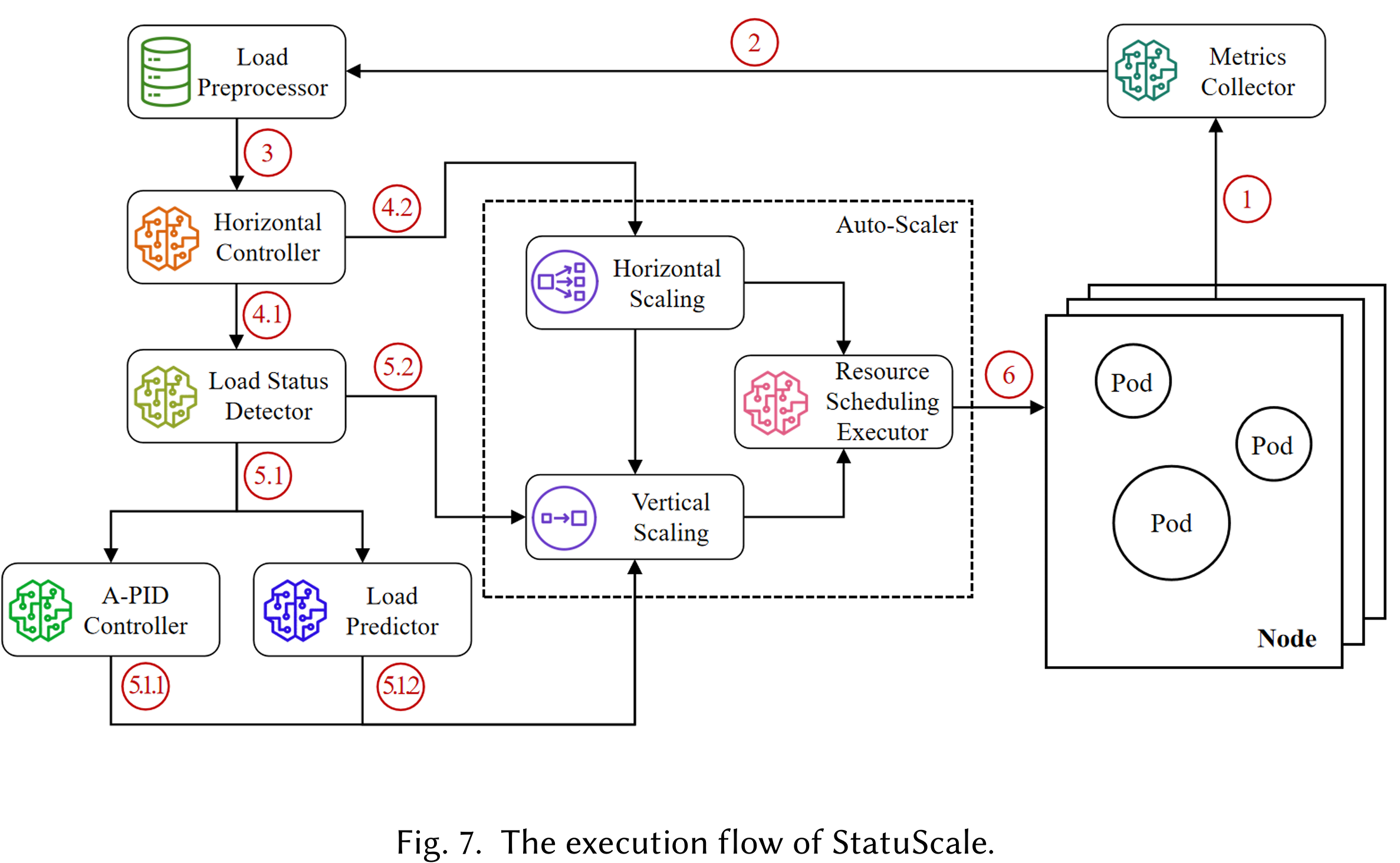
文章的讲述顺序和方法流程是不一样的,所以最开始让我有点费解,真正的整体流程如上图所示:
- 首先判断是否需要水平伸缩,判断方式为上文中提到的计算一段时间的 \(S_t\),并与上下阈值比较
- 如果需要水平伸缩,则计算\(R_n\),然后垂直细粒度资源调整(计算\(V(t)\))
- 如果不需要,则需要进行垂直伸缩判断
- 垂直伸缩检测需要对负载状态进行判断
- 如果状态为 “stable”,则用 LightGBM 预测负载
- 如果状态为 unstable,则使用 A-PID 控制器将资源利用率维持在稳定状态
值得注意的是,k8s的垂直伸缩应该会让容器重启(假如有10个副本,采用垂直伸缩后,相当于这10个副本都需要滚动更新),这真的会比水平伸缩快吗?
整体算法如下图所示:

实验评估
实验配置
- 集群配置:1 master + 2 worker,每个节点都是 4GB 内存 和 4 CPU cores。这个配置算比较小的了
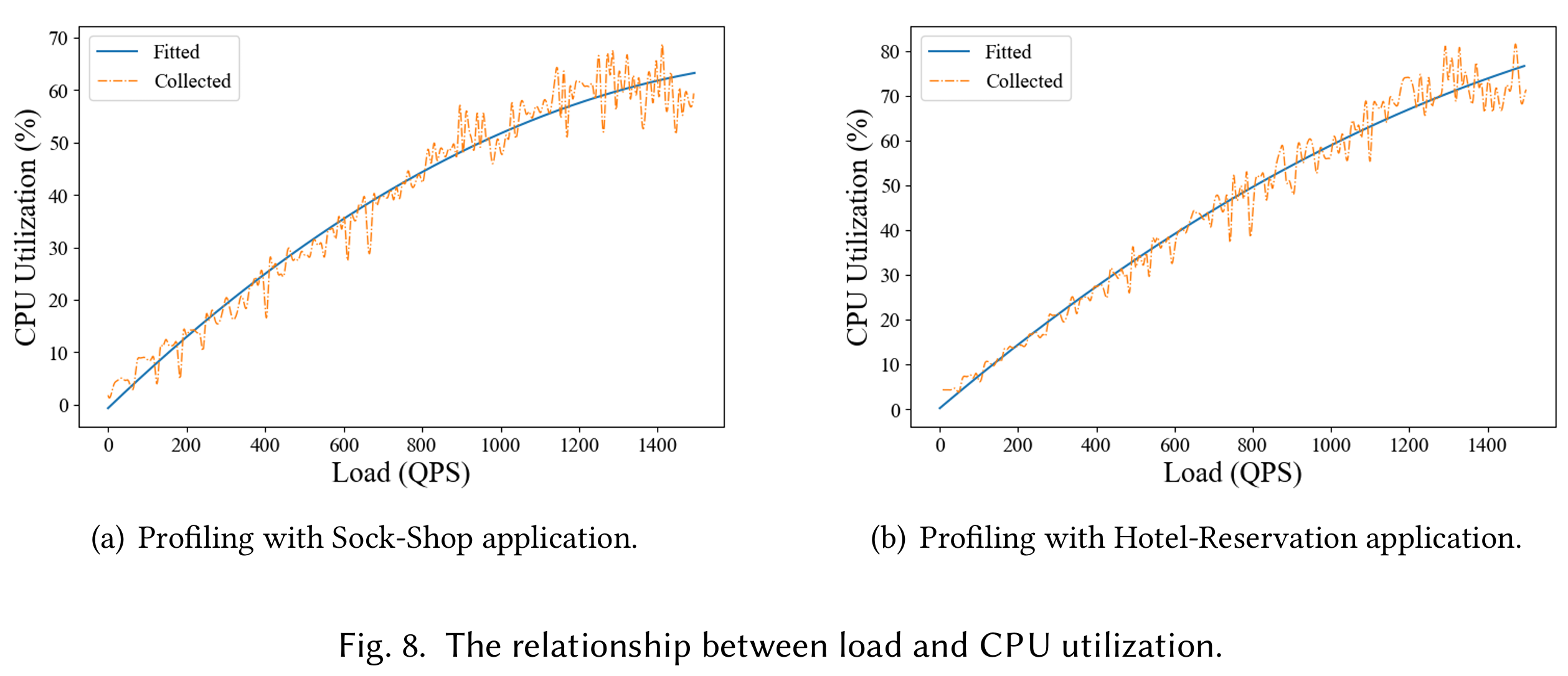
- 负载:文章的负载数据来自于 alibaba 的 cluster-trace-v20182,这个数据集里记录了8天内集群里机器和容器的资源使用情况,并调研了CPU负载和QPS的对应关系,如Fig.8所示,将CPU负载转化为QPS,文章使用这个作业负载作为实验的输入流量。负载的注入工具选择 Locust
- benchmark:选用 Sock-Shop 和 Hotel-Reservation
- 对比方法:选用了 GBMScaler,Showar,Hyscale
GBMScaler:选用 LightGBM 进行负载预测,但原文并没有提到如何用预测的结果进行 resource scalingShowar:经典的混合伸缩方法,基于 3-\(\sigma\) 准则进行垂直伸缩,每T秒预估当前CPU分配为过去一段窗口的\(\mu+3\sigma\);基于 PID 控制器进行水平伸缩(target设置为CPU利用率,\(k_P\),\(k_I\),\(k_D\)的更新与StatusScale一致)Hyscale:与kubernetes 默认弹性伸缩器很像,只需要指定CPU阈值,然后通过水平和垂直伸缩来达到目标
评估指标
文章主要考虑系统性能和资源消耗,使用的指标如下:
- response time (相同资源配额下,\(\int{R_t}dt\),\(R_t\)是t时刻分配的资源)
- SLO violation(相同资源配额下,\(\int{R_t}dt\))
- Accuracy of supply-demand relationships. 这个是看 resource supply
是否准确。在一段时间 \(T\)内,总共可分配资源为 \(R\),t 时刻的资源需求为 \(d_t\) (\(d_t\) 是通过 Fig.8
拟合出来的),有点类似于误差
- \(a_U=\frac{1}{T\cdot R}\sum_{t=1}^{T}{(d_t-s_t)^+\Delta t}\)
- \(a_O=\frac{1}{T\cdot R}\sum_{t=1}^{T}{(s_t-d_t)^+\Delta t}\)
- Correlation factor of supply-demand relationships. 这个指标用于衡量
supply curve 与 demand curve
的相似度(与上一个指标差别不大),本来应该用 Locust 收集的 QPS
转化为 demand 的 CPU 利用率,以及用 Prometheus 收集的
supply 的 CPU 利用率,然后计算两个曲线的
R-square(评估回归模型的性能指标)。但文章认为 Locust 与 Prometheus 是两套监控系统,收集周期和统计方式有所区别,所以改用Dynamic Time Warping算法来衡量两个时间序列的相似度:- 首先,将两个curve进行量纲对齐。比如将第一个 curve (\(X=\{x_1,x_2,\dots,x_m\}\))转到第二个 curve (\(Y=\{y_1,y_2,\dots,y_m\}\))的量纲下:\(x^\prime_i=(x_i-\mu_x)\times\frac{\sigma_Y}{\sigma_X}+\mu_Y\),\(x^\prime_i\) 是转化后的值
- 定义距离矩阵 \(D\),\(D_{i,j}\)代表 \(X\) 的时间点 \(i\) 和 \(Y\) 的时间点 \(j\)的距离,\(d(x_i,y_j)\) 代表 \(x_i\) 和 \(y_j\) 的欧氏距离(也可以用其他距离),\(D_{i,j}\)计算方式如下:
- \[ D_{i,j}=min\begin{cases} D_{i-1,j}+d(x_i,y_j)\\ D_{i,j-1}+d(x_i,y_j)\\ D_{i-1,j-1}+d(x_i,y_j) \end{cases} \]
- \(D_{m-1,n-1}\) 代表 curve \(X\) 与 curve \(Y\) 的最小距离,则
correlation factor计算如下:\(CF=max(m,n)/D_{m-1,n-1}\)
总实验
StatuScale
的目标有三个:①降低响应延时、②降低SLO违背率、③维持CPU利用率在目标水平(\(\pm1\%\))。
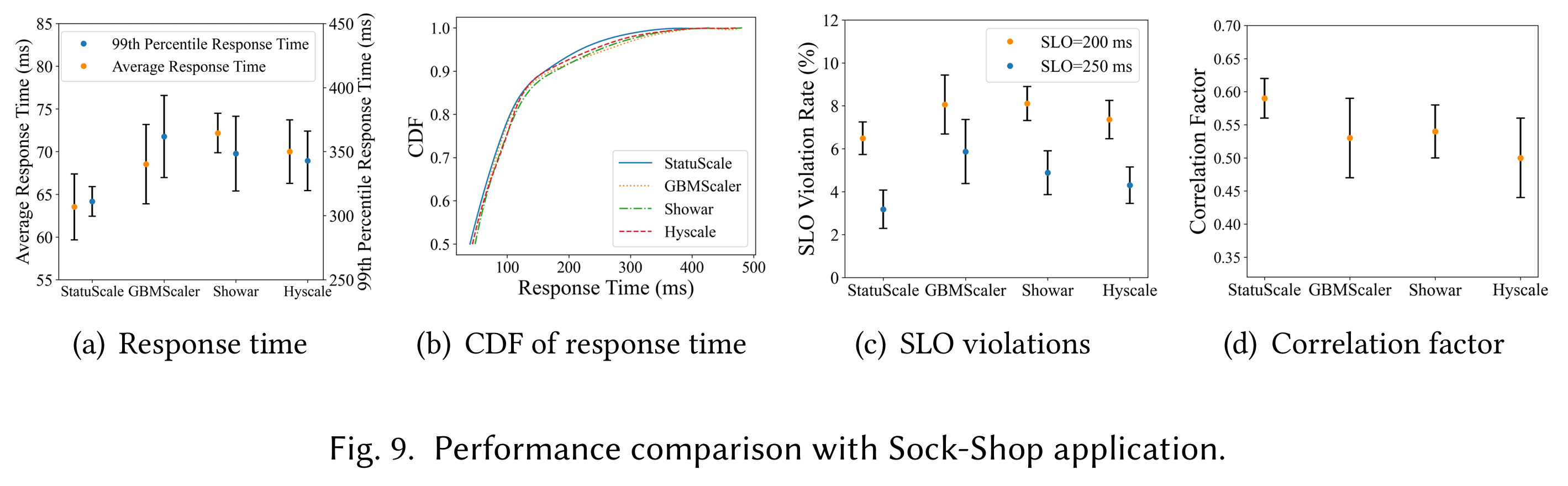
- Fig. 9(a)
展示了不同scaler的平均延时和P95延时的分布(Locust可以求得),可以看出
StatuScale的延时分布是比较偏低的,均值维持在50~70ms,P99维持在300多ms左右 - Fig. 9(b) 想展示的与Fig. 9(a)差不多,展示的是四个scaler的延时的累积分布直方图(CDF),P95基本维持在250ms左右,说明几个scaler都很有作用(私以为应该加上一个没有设置采样器的方法作为对比)
- Fig. 9(c) 计算了不同SLO阈值下的违背情况
- Fig. 9(d) 计算了
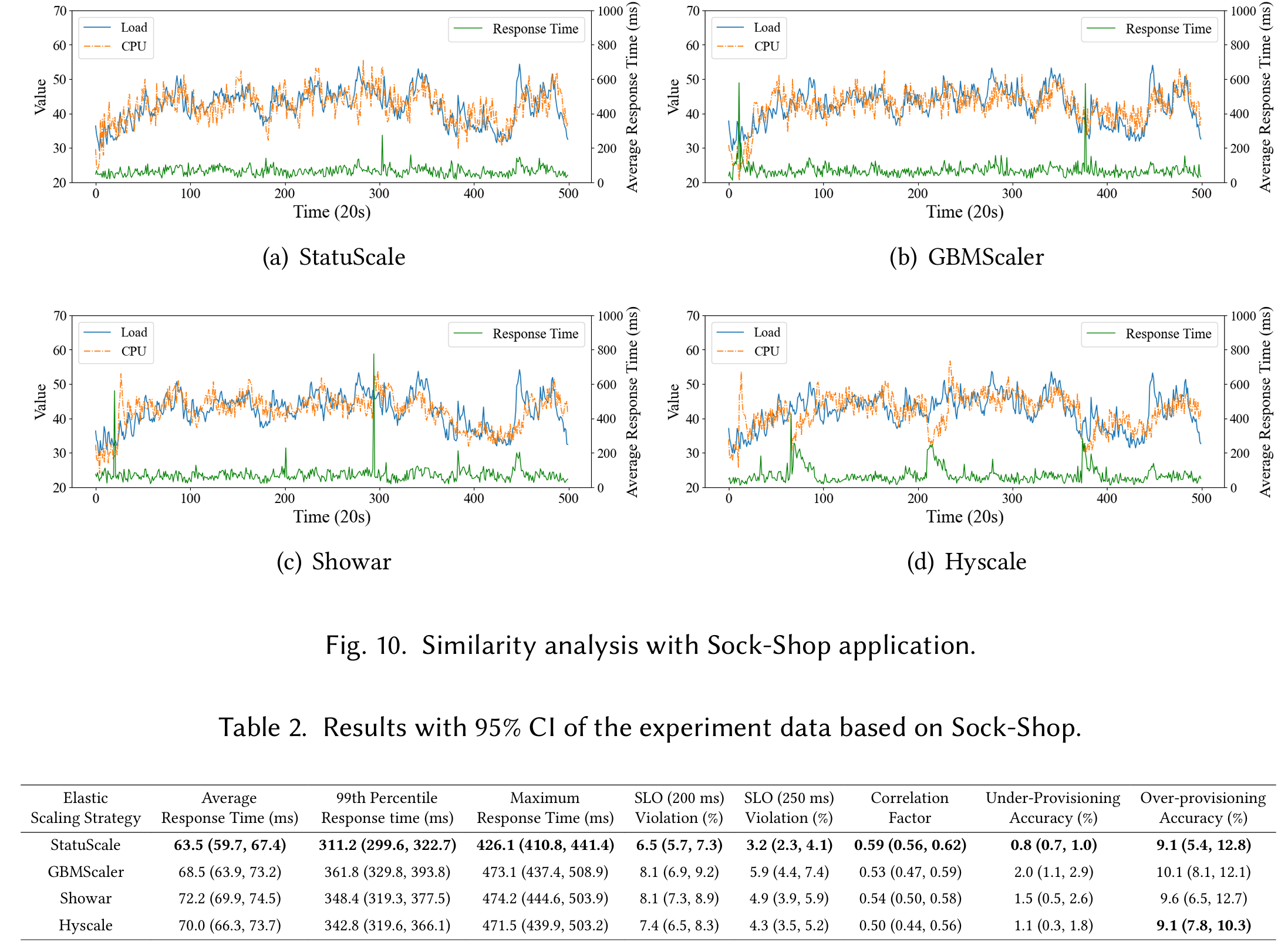
correlation factor,说明StatuScale的资源分配的曲线与负载波动(资源需求曲线)很相似。Fig.10 展示了CPU使用(这里难道不应该是分配的CPU吗?)和负载的相似度。表格是对图像结果的数据展示
StatuScale也在Hotel-Reservation上进行了实验,结果比较相似,就不贴上来了。
消融实验
消融 Status Detector Module
Status Detector判断当前负载是否
“stable”,如果 “stable”,则选择用
LightGBM预测负载,然后转换成CPU需求;如果
“unstable”,则用 A-PID
将CPU利用率控制在某个阈值。文章选择了3个变体,衡量它们的延时(为什么还要消融A-PID和LightGBM?为什么不衡量其他指标?)。实验在
Sock-Shop 上做,每组实验做3次
StatusScale\(^\Delta\):消融 horizontal scalerStatusScale\(^\circ\):消融 horizontal scaler,load status detector 和 A-PID 控制器StatusScale\(^*\):消融 horizontal scaler,load status detector 和 load prediction(LightGBM)
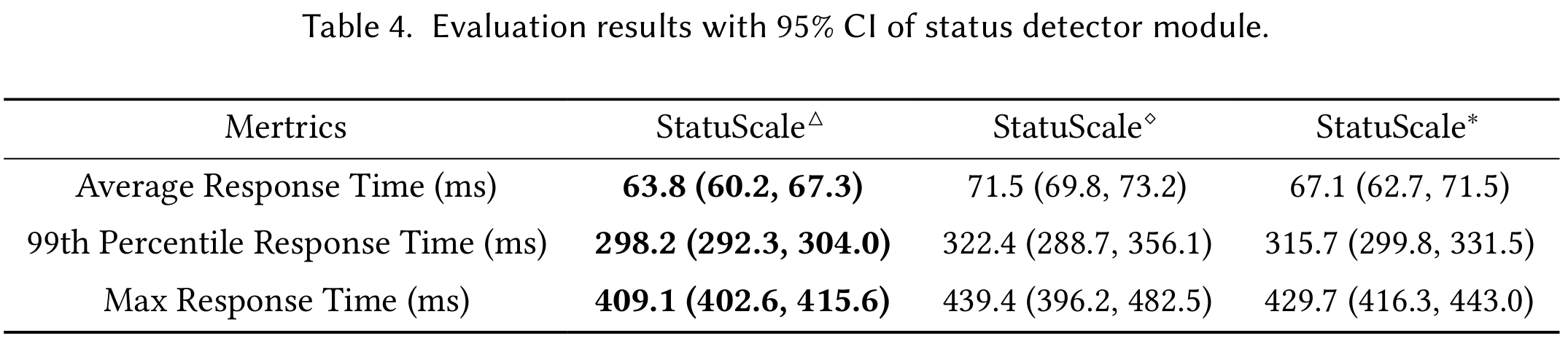
上述实验说明了 load status detector 对 load
prediction的影响很大(StatusScale\(^\circ\))
消融 Scaling Modes
vertical scaling 虽然能细粒度调节资源,但依然受限于单个机器硬件;horizontal scaling 又容易造成资源浪费。文章设计了2个变体,实验在 Sock-Shop 上做,每组实验做3次,但是加入了CPU使用率的对比:
StatuScale\(^\square\):只使用 vertical scalingStatuScale\(^*\):只使用 horizontal scaling
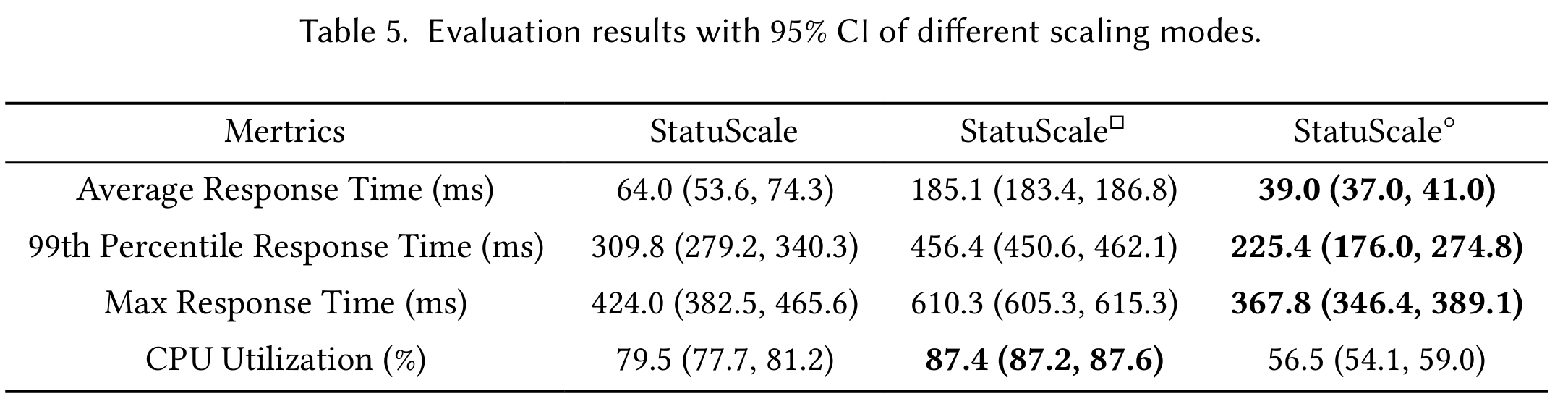
可以看出,horizontal scaling (StatuScale\(^*\))确实能最大限度降低延时,但是CPU资源利用率偏低;vertical
scaling(StatuScale\(^\square\))很难保证延时,但是CPU利用率高;StatusScale相当于在两者间做了均衡。