题目:L4: Diagnosing Large-scale LLM Training Failures via Automated Log Analysis
FSE 2025
作者:香港中文大学
摘要
训练个性化的大语言模型(LLM)需要大量的计算资源和训练时间。这个过程中,故障(failure)是不可避免的,而故障的出现使得LLM的训练浪费了大量的资源和时间。此外,在 LLM 训练中诊断故障也是一个费时费力的任务,因为 LLM 的训练通常设计多个计算节点:
- Node-level Complexity: 在单个节点上训练的 AI 模型,通常包含 AI accelerator(GPUs 或 NPUs)、AI toolkit(CUDA)、AI framework(Pytorch)以及AI algorithm。故障可能存在于上述任意一个地方。
- CLuster-level Complexity: LLM 的训练通常涉及上千个 AI 节点,这些节点之间有复杂的通信范式,这使得发生故障时很难通过自动化的方式定位到对应的故障 AI 节点
这篇文章首先进行了大量的实证分析,得出以下结论:
- 故障时间:大多数(74.1%)的故障发生在模型迭代训练时,这个阶段发生故障会导致大量的训练时间和资源的浪费
- 故障根因:随然故障原因多样化,但主要集中在 hardware 和 user-side faults。
- 诊断方法:日志在故障诊断中发挥重要作用,但是89.9%的案例仍然需要人工日志分析来进行故障诊断。并且日志量太大(每天产生 TBs),只有非常小一部分的日志是有用的
因此,文章提出了一种诊断 LLM 训练的故障诊断方法:L4,目的在于自动化识别故障相关的日志(failure-indicating logs),此外,L4 还会提供 failure-indicating nodes、failure-indicating stages、failure-indicating events 以及 failure-indicating iterations 等重要信息来辅助 SREs 进行故障诊断。
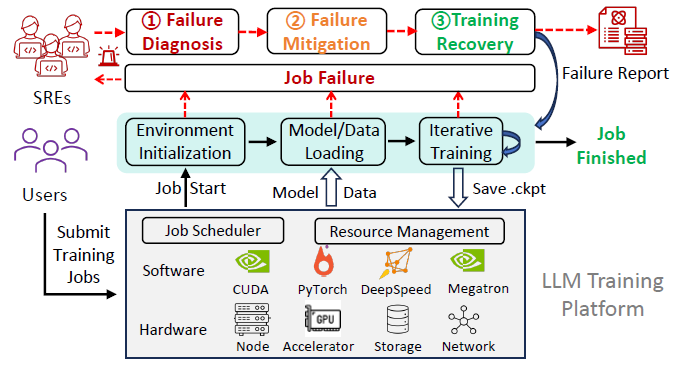
实证分析
文章分析了某平台上一年的428份故障报告,从以下三个方面进行分析:
- RQ1:LLM 训练中的故障现象
- RQ2:LLM 训练中的故障根因
- RQ3:LLM 训练故障诊断中常用的数据源
RQ1:故障现象
LLM 训练中的故障现象分为四大类:① launching failure,②
training crash,③ abnormal behavior,④
others

- 对于
launching failure(21.3%),这类现象通常发生在迭代训练开始前,原因一般是配置与版本问题,比如 GPU 驱动与 CUDA 版本不匹配,模型并行化配置错误等。- 对于
training crash(57.5%),这类现象发生在迭代训练时,起因一般是硬件故障(GPU、network),这种故障影响很大,会浪费大量训练时间和计算资源,即使有 checkpoint 这样的状态保存机制,时间的浪费也是不可忽视的- 对于
abnormal behaviors(16.6%),这种现象有点类似于性能降级,比如某个epoch花费了两倍的时间,训练突然停滞- 对于
others(4.7%),这类故障一般是基础设施类的,比如平台和存储,比例比较少
Finding 1:大部分故障(74.1%)发生在迭代训练时,会导致大量计算资源和训练时间的浪费。
RQ2:故障根因
LLM 训练中的故障根因分为四大类:① hardware fault,②
user fault,③ platform fault,④
framework fault
RQ2-1 hardware fault
Hardware Fault 又可细分为
- Network Fault:最常见,本质上是因为有太多 AI node 在交互协同,网络问题极容易导致训练的失败
- Accelerator Fault:Accelerator 就是GPU、TPU那些计算资源,与普通深度学习任务类似,单个 Accelerator 也会有内存故障等
- Node Fault:Node 是资源分配的单元,比如虚拟机。也会遭遇断电、磁盘问题等故障
- Storage Fault:训练涉及的数据集、模型、checkpoints等有几百GB,用户一般会存储到远程存储库中,在训练时下载,因此可能会出现访问问题
Finding 2:LLM训练需要大量计算资源,极易受 Hardware Fault 影响。其中,Network Fault 和 Accelerator Fault 是最常见的
RQ2-2 user fault
user fault 又可细分为
- Configuration Error
- Program/Script Bug
- Software Incompatibility
- Misoperation
Finding 3:User faults 是第二大故障根因,源于用户的误操作、脚本bug等
RQ2-3 Framework Fault and Platform Fault
这两类故障发生的极少,Framework Fault 一般是 PyTorch
那些深度学习框架中的故障。Paltform Fault
是训练平台的问题,包括资源管理不恰当等。这两类故障极难诊断故障,需要较深的领域经验
Finding 4:Framework Fault 和 Paltform Fault 虽然发生极少,但诊断起来相当困难
RQ3:故障诊断数据源
现在诊断 LLM 训练故障还是人工分析居多,文章中提到:
诊断 LLM 训练故障平均需要 34.7 小时,而 41.9% 的故障需要 24 小时以上的诊断时间
这就迫切需要自动化的故障诊断方法来减少人工分析成本。文章首先对428份故障案例进行分类,分为以下三种:
- Log-only diagnosable
- Non-log diagnosable
- Hybrid diagnosable
然后分别分析每个案例的 training log 来进行故障诊断,以下是分类结果

同时发现每个故障案例在故障时间段平均有 16.92GB 的 training log
Finding 5:training log 能解决 89.9% 的故障,但是日志量太大,需要自动化分析手段来减少人力成本
现有方法
现有方法大致通过
logging level,event frequency,error semantic
来提取异常log,即
failure-indicating logs。文章通过统计发现这些方式都有一定的局限性:
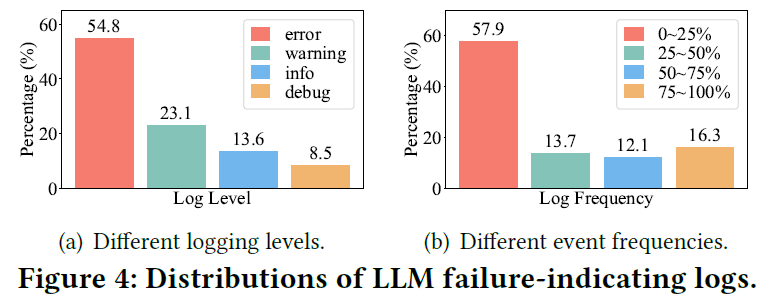
logging level:现有方法有许多是根据日志级别来进行筛选的。文章首先统计了failure-indicating logs中不同级别的日志分布,如 Fig.4 (a) 所示,虽然大部分是 Error-level,但是仍有大量其他级别的 logs 是故障相关的。此外,并不是所有 Error-level 的 logs 是与当前故障相关的,比如有些 Error logs 是无法写入 checkpoints,但一些故障容忍策略可能会采用重写措施,只要重写成功,那么对当前训练是没有影响的Event Frequency:有些方法是根据日志的频率来筛选故障相关日志,比如低频日志更有可能是异常的。如 Fig.4 (b) 所示,仍然有大量failure-indicating logs的频率并不低。此外,基于频率的筛选可能更适合微服务,不适用于 LLM 训练,因为微服务是无状态的,日志的频率分布可能并不会随时间分布发生较大改变,而 LLM 训练是顺序的、分阶段的,有些日志只会出现在特定阶段,这些日志的频率很低,但与故障无关。Error Semantic:也有些方法通过深度学习来提取日志的错误语义信息来识别failure-indicating logs,但是这种方法是不稳定的,因为即使是成功训练的job也包含有error semantic
Finding 6:现有的 failure-indicating logs 提取方法基于level, frequency 和 semantic,但都不适用于 LLM 训练的故障诊断
L4 方法
文章提出了自动化的面向 LLM 训练的故障诊断框架:L4

1. Log Preprocessing
这一块与之前的方法相同,都是用 Drain 提取日志的模板,将 log sequence 变成 event sequence
2. Cross-job Filtering
这一块动机很直观,因为用户在提交作业到平台进行大规模训练(large-scale nodes)时,通常在小规模的节点上已经测试通过了。所以这一块会将成功执行的日志(Normal logs)与在大规模节点上的失败日志(failed logs)进行比对,删除 failed logs 中噪声 events。
具体做法为:将 Normal logs 进行解析得到一个 normal event pool:\(N=\{e_{n1}, e_{n2}, ...\}\),然后将这些 events 按照时间顺序排列,并逐个移除 failed logs 中对应的events,这些events都是正常的,failed logs 剩下的 events 都是极大概率是故障相关的。这里有个问题,不同规模的训练节点会不会导致日志模式发生变化?
这个模块的前提是有小规模训练成功的日志,当这个前提不满足时,则无法删减 failed logs的噪声events,就直接将 failed logs 解析后进行后续步骤
3. Spatial Pattern Comparison
这个步骤主要是为了定位 failure-indicating nodes 和
failure-indicating logs。核心思想是:由于负载均衡,正常情况下所有的
AI nodes 的日志几乎是一样的。所以可以很轻松找到
failure-indicating nodes
首先将每个 node 的 event sequence
按照发生次数进行特征构建,得到 event vector:\(V=[c_1,c_2,...c_n]\),\(c_i\) 代表 \(i\)-th event 的次数。然后对所有 node 的
event vector 采用 Isolation Forest 进行异常检测。
由于 Isolation Forest
可以记录特征参与分割的次数,从而能够判断特征(event)的重要性,所以进一步找到
failure-indicating logs
4. Temporal Pattern Comparison
这个步骤主要是为了定位 failure-indicating stage 和
failure-indicating iteration,即故障发生的时间。
stage 的确定很简单,L4 好像直接使用的是日志中自带的规则,能直观知道 event 在哪个 stage
文章还要定位到故障的 iteration。首先文章有个前提假设,即 event sequence 在迭代时基本遵循一定的模式,如果某个 iteration 发生了明显偏移,则视为异常
具体做法为:首先将 iterations 按照 10 个一组进行滑动窗口划分。采用 Dynamic time warping(DTW)计算不同窗口间的距离,然后通过 3-sigma 方法对距离进行异常检测,就能找到异常的 iteration 了
最后,就能将故障相关的 logs、events、nodes、stages、iterations 交给 SREs 了。
实验设计
实验主要是对 failure-indicating logs 和
failure-indicating nodes
的定位进行了准确率评估,然后给了几个成功案例