题目:Self-Evolutionary Group-wise Log Parsing Based on Large Language Model
ISSRE 2025
作者:中科大杭州高等研究院,清华大学
摘要
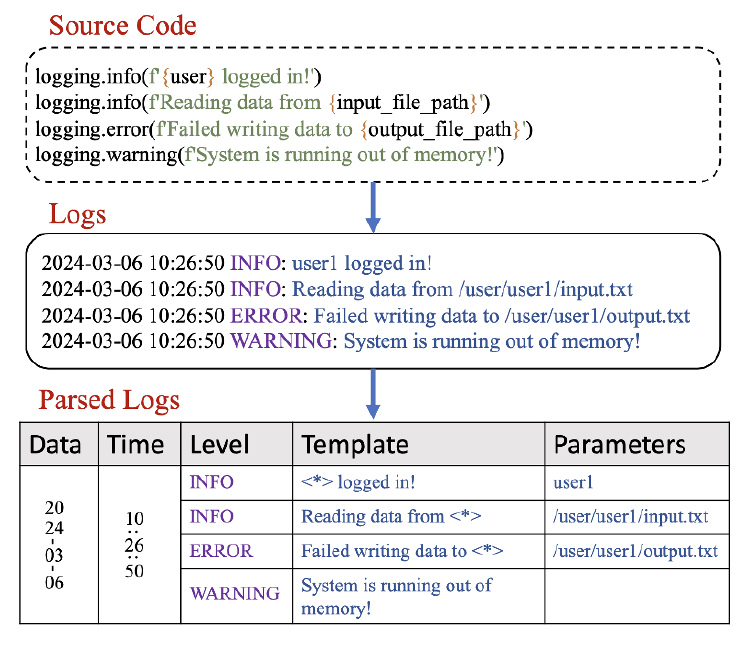
日志解析是一种将半结构化日志转化为结构化模板的技术,它是各种日志分析任务(比如异常检测、日志理解)的前提。
现有的日志解析方法大多基于领域专家制定的启发式规则,这些规则在系统发生变更时就无法适用了。因此,不少研究采用大模型来进行系统无关的日志解析,但仍然存在两个显著问题:
- 大模型需要在 Prompt 中加入人工标注的日志模板
- 大模型的日志解析效率太低
因此,文章提出一种自演化的日志解析方法 SelfLog,将相似的历史解析的模板作为 Prompt 中的提示词,以实现自我演化和零标注。此外,还引入一种基于N-Gram的日志分组器与日志匹配器,按组处理和解析日志,通过减少大模型调用次数来提升效率。
背景
日志解析
日志解析会将每条日志分割为常量部分和变量部分。常量部分也称为模板。如图4所示,在有源码的前提下,我们能够很轻松区分这两个部分。然而大多数时候大量第三方依赖库的源码是不可见的,
所以开发了许多数据驱动的日志解析技术,这些技术分为有监督和无监督两类:
- 无监督:通过启发式规则和频率统计来提取模板。缺陷是制定规则需要领域经验,且对于新log数据集要重新制定规则
- 有监督:通过人工标注的 <log, template> 键值对来训练,缺陷是对训练数据的分布敏感且在新log上表现较差
由于日志本质上是程序员写的语句,包含了大量语义信息。大模型技术擅长于理解语句,并且有很强的 zero-shot 推理能力,所以现有研究开始尝试用大模型进行日志解析,但仍然存在两个显著问题:
- 大模型需要在 Prompt 中加入人工标注的日志模板案例。这个案例的质量非常重要,随着系统更新,需要人工重新标注案例
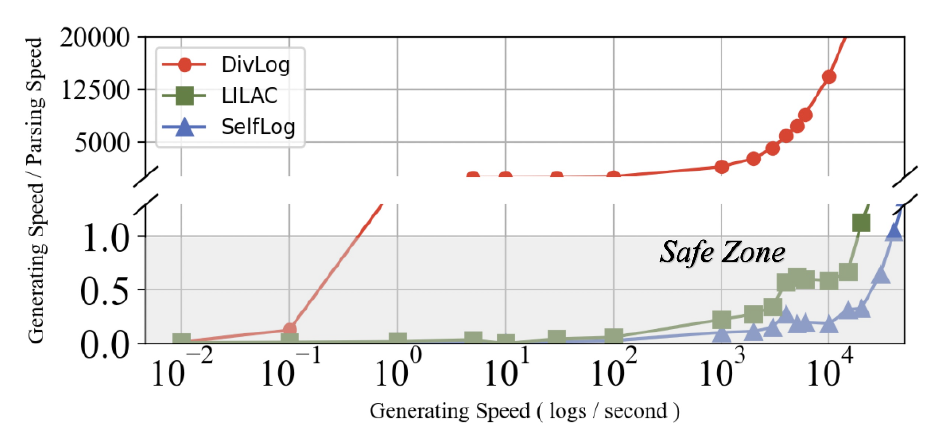
- 大模型的日志解析效率太低。现有的 LLM 日志解析方法每秒只能处理不到 15000 条日志,如果低于日志产生速度,则非常危险。
所以现在迫切需要一种高效率、高准确率的日志解析方法
SelfLog 方法
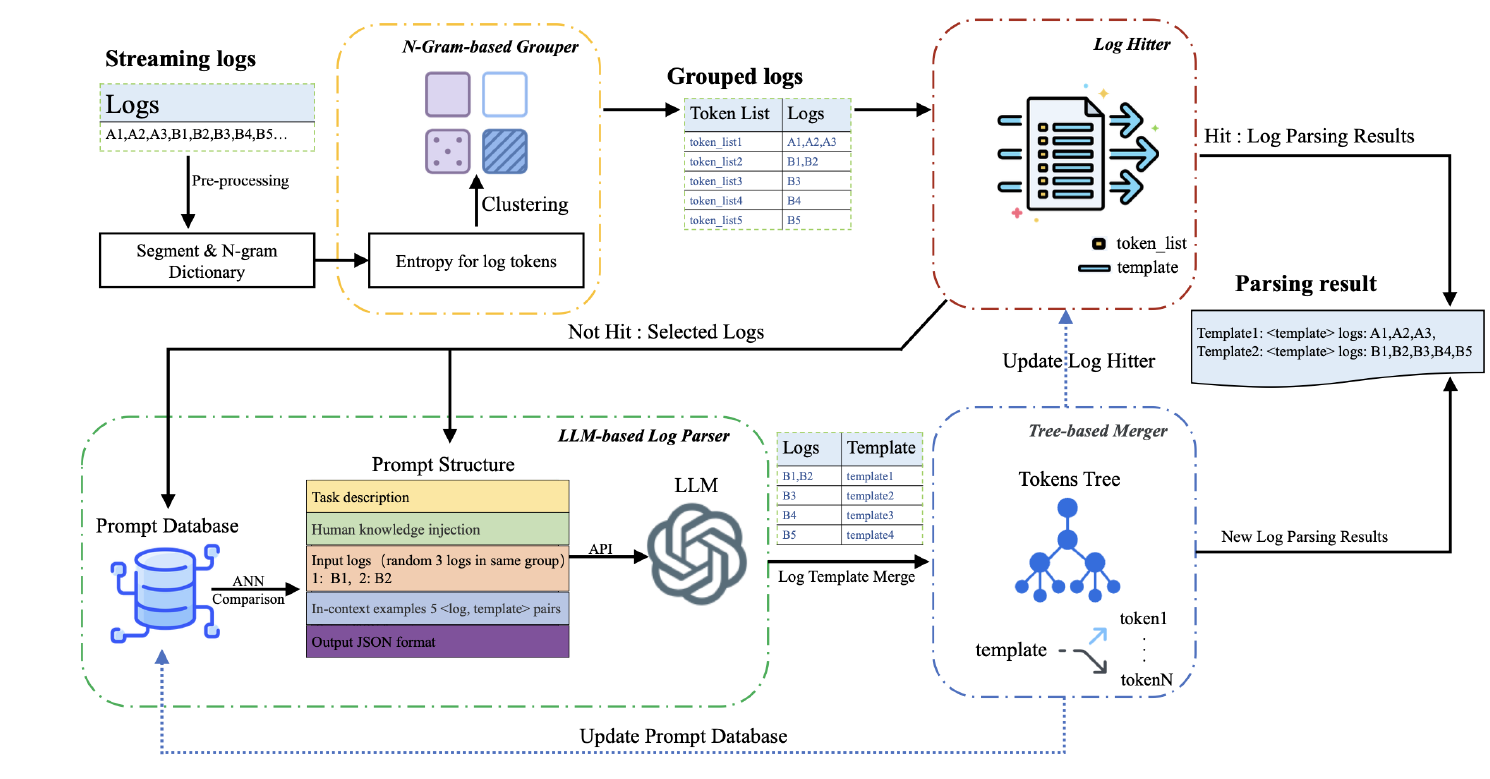
文章提出了一个基于大语言模型自演化日志解析工具 SelfLog,架构图如上所示,整体分为四个部分:
- N-Gram-based Grouper:这个部分先对日志进行聚类和分组,并提取常量部分,以组为单位让大模型进行解析,减少大模型的调用次数
- Log Hitter:这个部分会检查 Grouper 的常量部分是否有现有模板与之匹配,如果是已知的,则无需调用后续步骤
- LLM-based Log Parser:以组为单位进行日志解析,输出组的模板
- Tree-basd Merger:修正错误的日志和模板
预处理
预处理部分主要关注几个部分: - 将日志中的时间、级别去掉,重点关注日志的内容 - 设置分隔符——满足“[A-Za-z0-9*]+”正则表达式的视为token,其他都被视为分隔符(比如_, |) - 移除日志中的纯数字 - 移除日志中的超低频token(可能是前缀或者后缀)——3个或者少于3个
预处理后,每个日志将会转变为一个 token 列表
N-Gram-based Grouper
这一个模块的目标是:识别并移除 token 列表中的 variable,将剩余的 token 用作分组
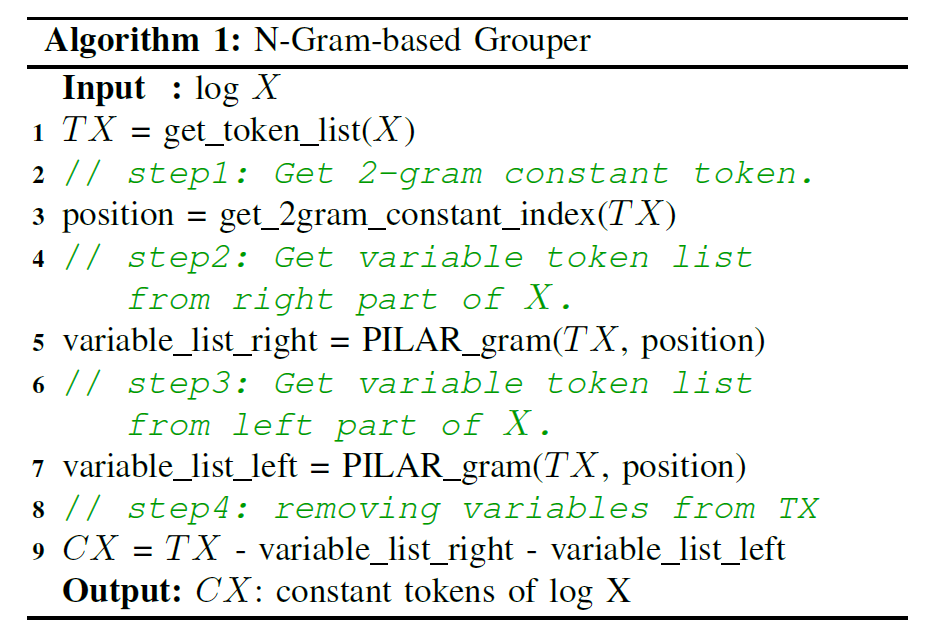
上图是这一块的伪代码:
TX = get_token_list(X)输入:预处理后的 token listposition = get_2gram_constant_index(TX)这一步是输出权重最大的长度为两个词的 token 的索引。假设常量部分一般都是高频词,因为它会稳定出现在衍生的日志中,所以高频词会给较高的权重。variable_list_right = PILAR_gram(TX, position)从 position 开始向右移动,每个 token 的分数计算为 (与邻居共同出现的次数 / 邻居出现的次数),然后通过3-sigma 判断分数是否异常,如果低于阈值,则判断为 variablevariable_list_right = PILAR_gram(TX, position)与 3 同理
经过上述伪代码,token 列表中将只剩下常量 token,然后依据常量 token 列表进行分组,组的 key 值即为常量 token 列表
值得注意的是,即使这一块没有识别出所有的 variable,也可以让后续的 LLM-based Log Parser 和 Tree-basd Merger 来修正
Log Hitter
这个模块的目标是:检查不同组的 key 是否在历史中出现过,如果命中,则直接返回模板;如果没命中,则将这个组中三个编辑距离最大的logs作为 LLM-based Log Parser 的输入。
Log Hitter 比较简单,维护了一个字典,键是 token 列表,值是模板。LLM-based Log Parser 的输出也会更新到字典中
LLM-based Log Parser
这个模块的目标是:对三个同组的 logs 提取模板

上面是 prompt 模板,用的大模型是 GPT 3.5,输出固定为 分析过程 和 模板
需要注意的是 prompt 中的蓝色板块,这一块是实现 self-evolution 的关键,核心思想是: > 建立一个 Prompt Database 记录日志和模板,当日志需要解析时,采用类似 RAG 的技术检索到最相似的历史日志和模板作为 example,放到 prompt 中去
Tree-based Merger
事实上,上述过程仍然还会有变量被遗漏,如下图所示
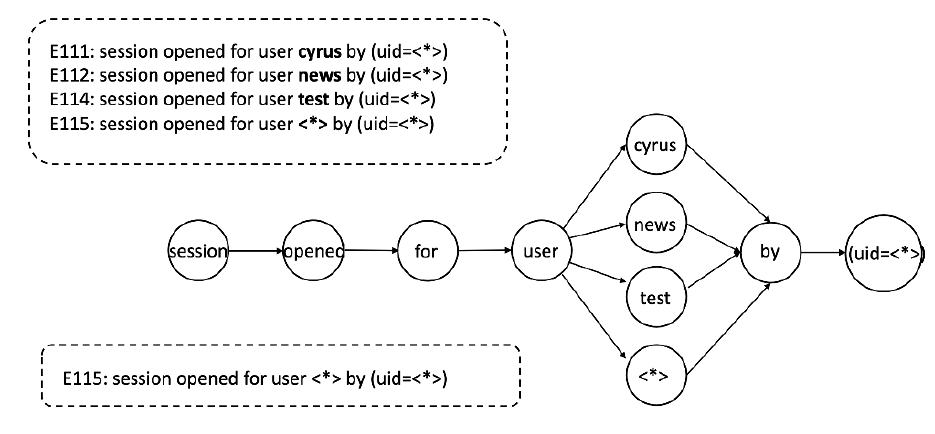
最开始的时候,只有 user 为 cyrus 的日志,所以会把 cyrus 视为常量,但是随着越来越多 user 的出现,cyrus 应该被划分为变量,所以需要一种后处理机制
如上图所示,SelfLog 维护了一棵树,这棵树是实时更新的,然后执行合并操作,这一块感觉讲的不是很清楚,也不知道是人工合并还是自动化合并
实验
主实验是在 LogPAI 上进行性能对比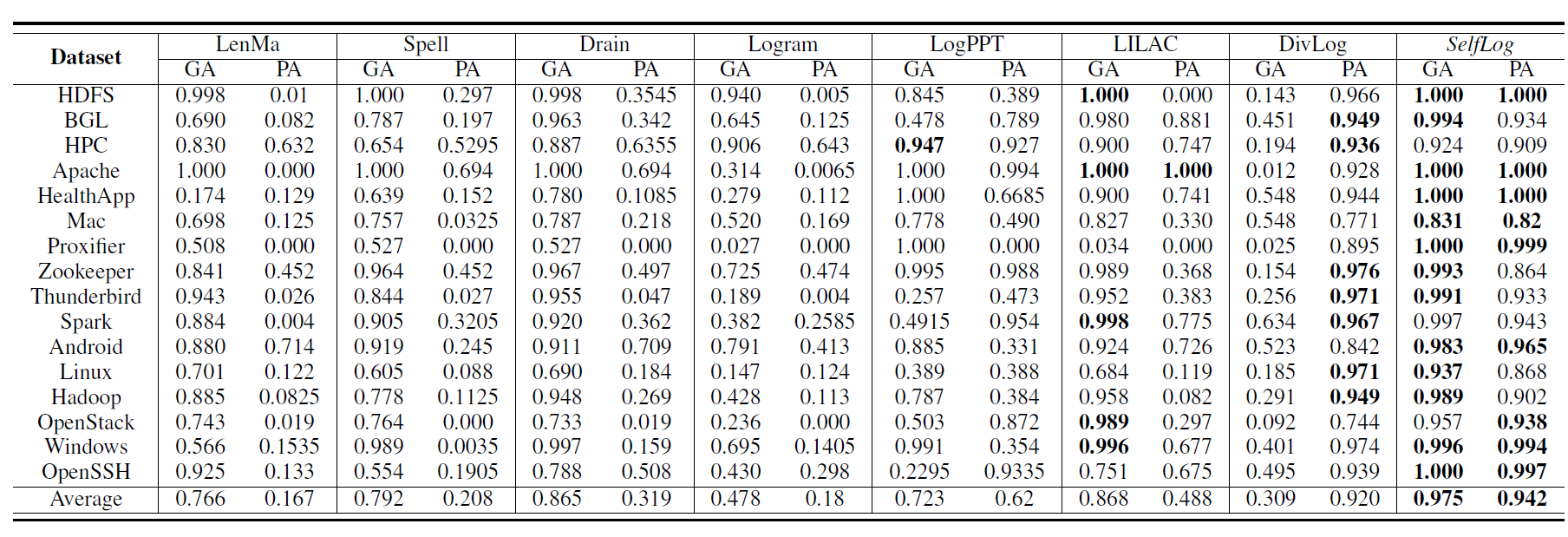
参数和消融实验就不放了
效率实验是在不同日志产生速度和解析速度上的对比