题目:Cross-System Categorization of Abnormal Traces in Microservice-Based Systems via Meta-Learning
FSE 2025
作者:赫尔辛基大学
摘要
微服务系统(MSS)可能因为复杂性和动态性发生可靠性问题。虽然现有的
AIOps 方法能够通过异常 traces
来定位根因服务,但是仍需要人力来进一步确定根因的故障类型。因此,文章提出了一种故障诊断框架
TraFaultDia,将故障根因和故障类型绑定在一起,给出结果。
文章将故障诊断视作一个分类任务。文章引入了元学习(meta-learning),即每次在有限样本和有限标签组合下进行训练,然后在测试时用极少的有标签样本微调,以应对新故障类型和新系统。文章在两个公开数据集上进行评估,无论是在新故障类型还是新系统上都取得了非常高的性能。
背景
现有的 AIOps 算法大多是定位到根因服务,没有进一步给出故障类型。特别是对于有些根因不是微服务的故障,比如机器资源不足、虚拟环境资源配置错误等,简单地定位根因服务没有意义。此外,大型 MSS 的 trace 数据量巨大,人工去分析故障类型显得不切实际。
因此,文章决定将根因服务和故障类型一起给出,整体规范如表所示,文章定义了一个概念:
failure category: pod associated with a fault type
比如表格中的 (F1-F30, B1-B32) 都是 failure category。注意,有些 failure category 是没有对应的 pod 的。

总之,文章把问题简化为了一个多分类问题,但是我有点疑问,对于从未出现过的根因和故障类型的组合,应该怎么办?
挑战
文章总结了进行故障诊断的三个挑战:
- MSS 异质性:每个 MSS 在业务逻辑和服务组成上有显著不同,比如 TrainTicket 有 45 个微服务,OnlineBoutique 有 12 个微服务,很难设计一个统一的、适用于所有系统的故障诊断方法
- MSS 高维度、多模态 trace
数据:现在很多系统的trace与日志是关联在一起的,包含时序数据、文本数据以及ID
- 不同故障类型的trace数据量不均衡:如下图所示,以 TrainTicket 为例,有些故障类型只有26条数据,而有的却有 2546 条

方法
TraFaultDia 的框架非常清晰,分为两个部分:
- AttenAE:这一块用无监督的方式训练了一个 trace 的编码器,结构是常见的自编码器。这一块用于对 trace 进行编码得到特征
- TEMAML:这一块对 trace 特征进行故障诊断,backbone 是一个 transformer-encoder 网络,采用了 meta-learning 的机制进行学习
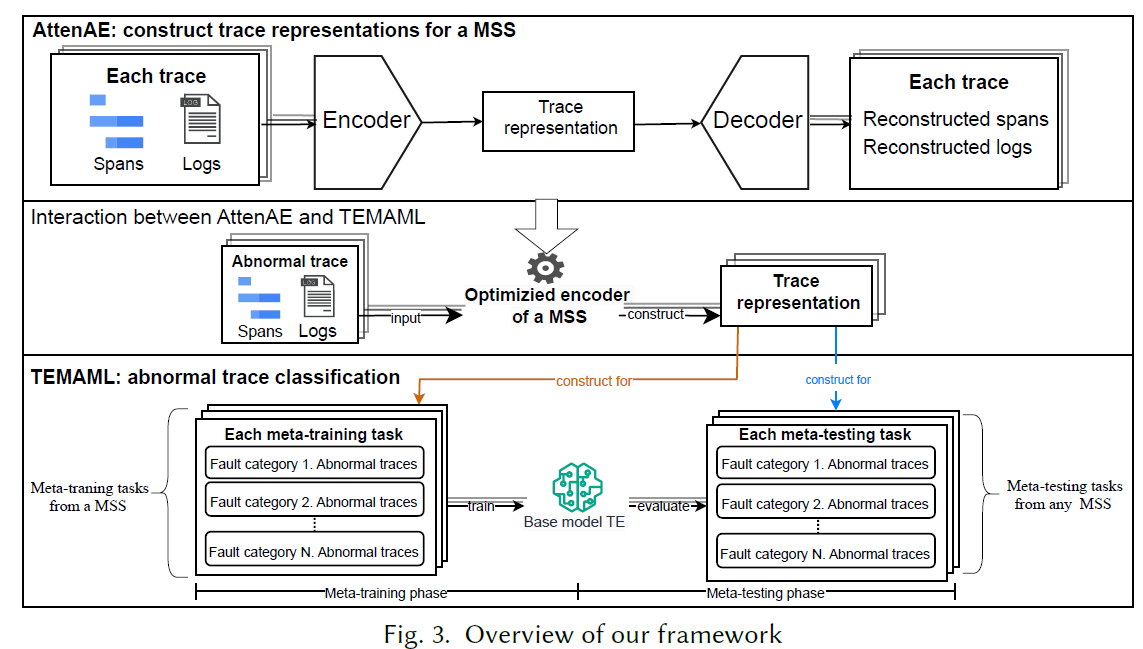
AttenAE
有大量工作设计了专门针对 trace 的表征方法,TraFaultDia
的表征方式也有其独到的地方,由于某些系统 trace 和 log
是关联在一起的,所以需要分别进行表征,具体流程如下图所示:
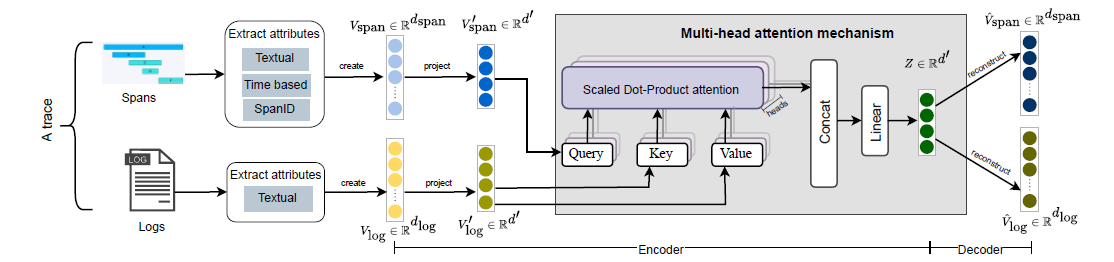
针对 trace:trace 包含的信息大体分为:
- time-based:比如每个span的延时,文章直接把每个span的延时拼接为一个数组 \(V_{numeric}\)
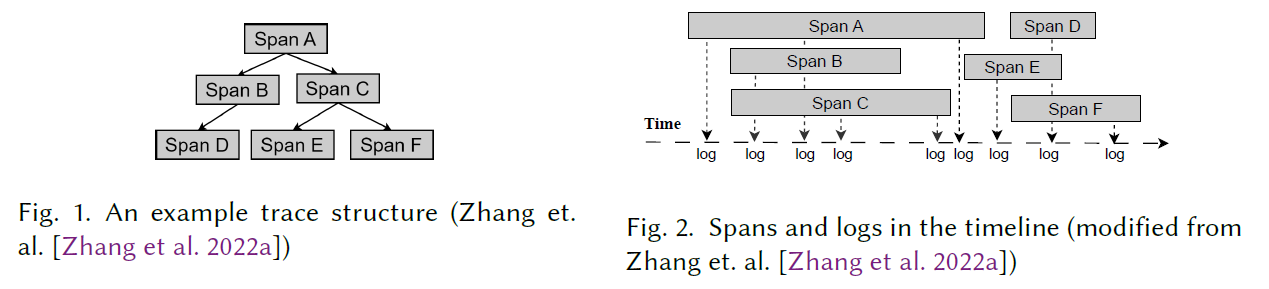
- identity:对于不同的 spanID,这里采用了分层统计的方法,比如上面 Fig.2 的 Span A, Span B, Span C, Span D, 和 Span E 的 spanID 可以重写为:\(V_{span_id}\)=[1.0, 1.1, 1.2, 2.0, 3.0],共同的前缀表示这些 span 属于同一个父级操作或服务
- textual:如何表示一个trace经过了哪些操作呢?这里将所有的 span 的 service operation 进行编码得到特征然后平均池化得到 \(V_{operation}\)。这里的具体操作分为:①预处理 ② tokenization(用 WordPiece 分割成 subwords) ③ BERT 提取语义信息
最后拼接三个特征得到trace级别的表征 \(V_{span} = Concat(V_{numeric}, V_{span\_id}, V_{operation})\)
- 针对 log:因为系统不断变化,日志模板也会变化,所以文章认为通过日志模板得到特征不可靠,应该关注语义信息,编码方式还是 trace 表征方法中textual的三步,得到 \(V_{log}\)
现在已经得到了初步的表征 \(V_{span}\) 和 \(V_{log}\),接下来就是自编码,文章在此处引入了多头注意力机制:

所以,对于一个 trace 集合 \(Tr = \{Tr_1, Tr_2,...,Tr_n\}\),可以通过上述方法得到表征集合 \(Z=\{Z_1,Z_2,...,Z_n\}\),然后再解码得到还原后的特征 \(\hat{V}_{span}\) 和 \(\hat{V}_{log}\),Loss是与原特征的L2范数:
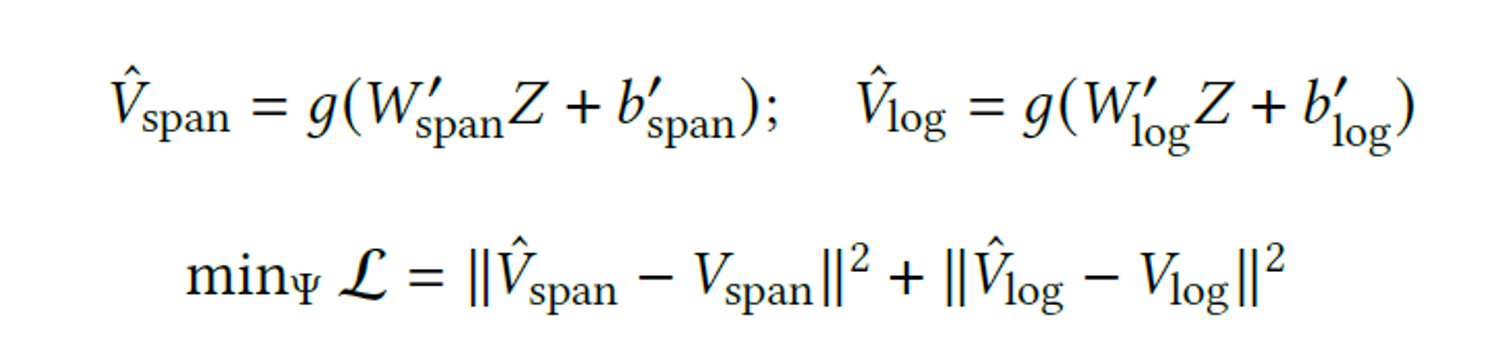
TEMAML
TEMAML 的骨架是 transformer-encoder(TE),输入是 trace 表征集合 \(Z\),输出是 failure category。整个过程分为两部分:
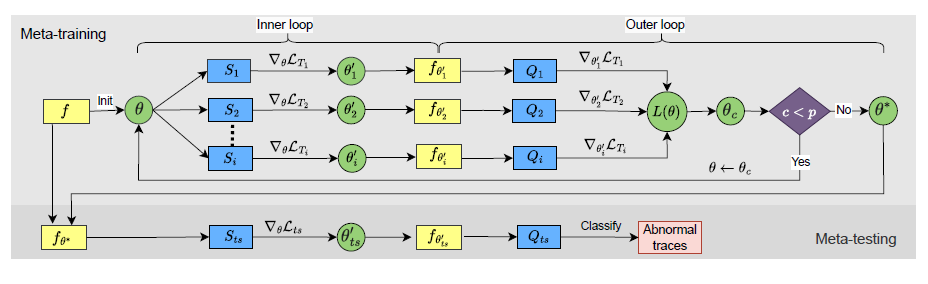
Meta-training:该阶段旨在训练 TE 找到能够快速适应任何 MSS 分类任务的鲁棒参数。首先定义一个概念 meta-training tasks,表示为 \(T=(S, Q)\)。其中每一个 meta-training task, \(T_i=(S_i, Q_i)\) 都是一个多分类任务,\(S_i\) 和 \(Q_i\) 分别表示第 \(i\) 个任务的 support set 和 query set。注意,support set 和 query set 均来自训练集
- support set \(S_i=\{(z_{ij}^{spt}, y_{ij}^{spt})\}_{j=1}^{N\times K}\) 遵循 N-way K-shot 的初始化方法,即有 N 个独特的标签(failure category),每个标签下有 K 个样本。\((z_{ij}^{spt}, y_{ij}^{spt})\) 表示 trace表征集合和对应的failure category。注意,meta-training tasks 中每个任务虽然都是 N 个标签,但是 N 个标签的组合可能不一样,比如总共有 20 个 failure categories,N 为 5,则每个任务的标签都是从 20 个中选 5 个
- query set \(Q_i=\{(z_{ig}^{qry}, y_{ig}^{qry})\}_{g=1}^{N\times K}\) 有 N 个独特的标签(failure category),每个标签下有 M 个样本,M > K,i.e., (\(|Q_i|>|S_i|\))
训练过程有两个循环:① inner loop 和 ② outer loop,定义基础模型为 \(f\)
inner loop: 在 \(S_i\) 上操作,负责对每个任务进行分别学习,并更新模型 \(f\) 参数 \(\theta\)
- 针对任务 \(T_i\),学习率为 \(\alpha\),参数更新如下:\(\theta_i{'}=\theta-\alpha \nabla_{\theta}\mathcal{L}_{T_i}(f_{\theta}(S_i))\)
outer loop: 在 \(Q_i\) 上操作,对于所有任务进行优化,并更新模型 \(f\)
- 在所有任务上进行优化:\(\min\limits_{\theta} \mathcal{L}(\theta) = \sum_{T_i \in T} \mathcal{L}_{T_i}(f_{\theta'_i}(Q_i))\)
- Meta-testing:该阶段目的是适应任意 MSS 的新的多分类任务。对于某个特定的测试任务 \(T_{ts}=(S_{ts}, Q_{ts})\),在 \(S_{ts}\) 上进行微调,然后用 \(Q_{ts}\) 进行测试
实验
实验采用的数据集来自 TrainTicket 和 OnlineBoutique,配置如下:
- TrainTicket:20 基础故障类型 + 10 新故障类型
- OnlineBoutique:22 基础故障类型 + 10 新故障类型
训练配置:
- meta-training:4 meta-training tasks (基础故障类型);5-way 5-shot;query set M=15
- meta-testing:50 meta-testing tasks (新故障类型);5-way 10-shot;query set M=15
文章设计了四个实验来证明 TraFaultDia
在不同场景下的性能:
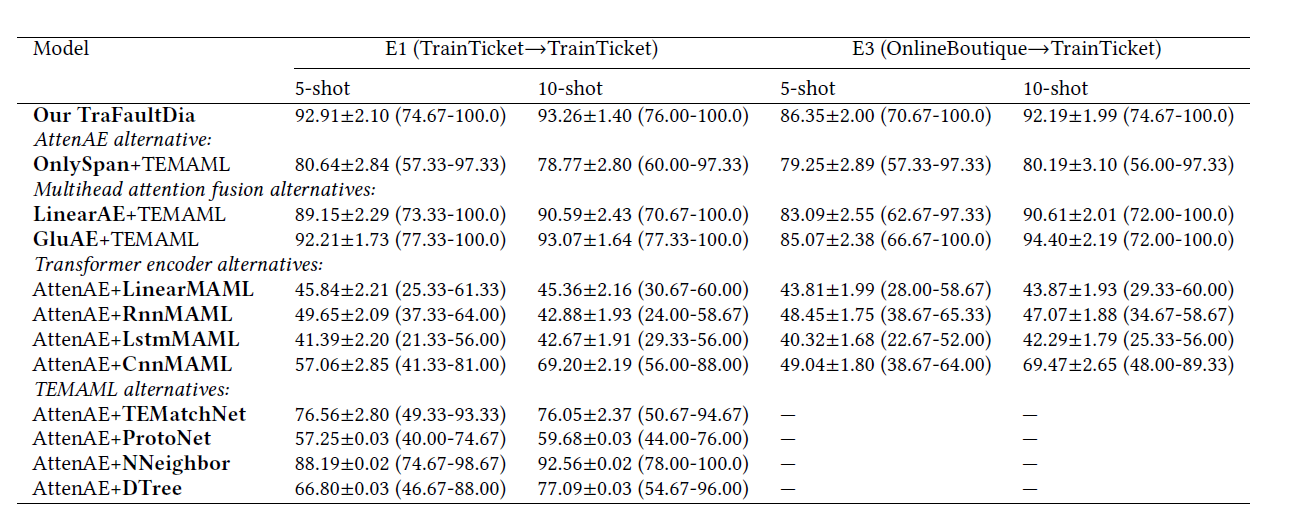
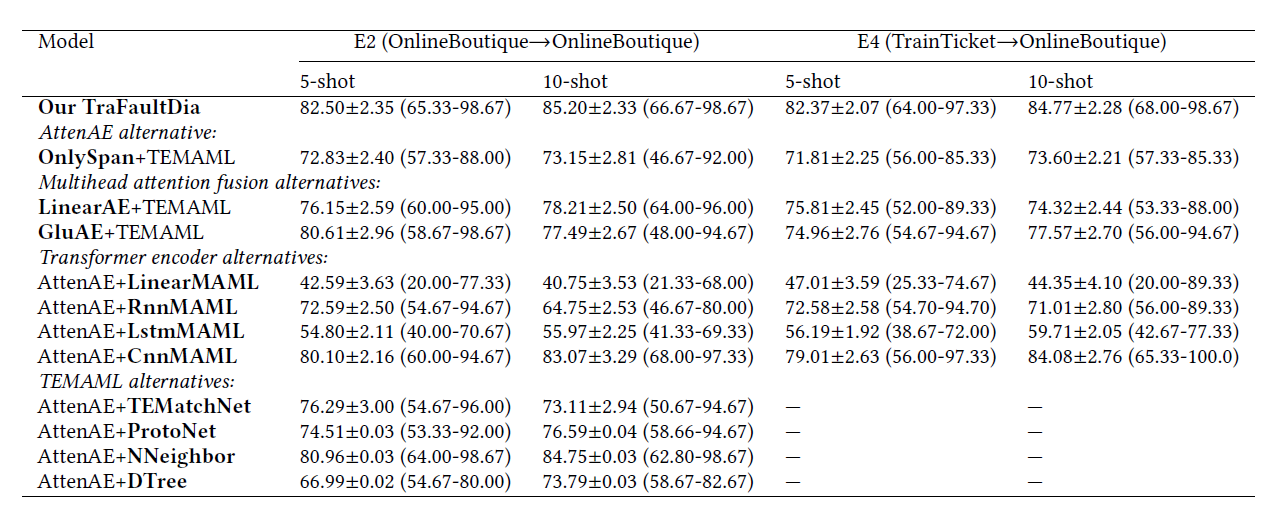
- E1 (TrainTicket → TrainTicket) 在 TrainTicket 的 4 meta-training tasks 训练,在 TrainTicket 的 50 meta-testing tasks 测试
- E2 (OnlineBoutique → OnlineBoutique) 在 OnlineBoutique 的 4 meta-training tasks 训练,在 OnlineBoutique 的 50 meta-testing tasks 测试
- E3 (OnlineBoutique → TrainTicket) 在 OnlineBoutique 的 4 meta-training tasks 训练,在 TrainTicket 的 50 meta-testing tasks 测试
- E4 (TrainTicket → OnlineBoutique) 在 TrainTicket 的 4 meta-training tasks 训练,在 OnlineBoutique 的 50 meta-testing tasks 测试
下面是实验结果