题目:OpenRCA: Can Large Language Models Locate the Root Cause of Software Failures
来源:ICLR 2025
作者:香港中文大学(深圳)
摘要
大模型(LLM)推动了软件工程领域的实质性进步。然而现有的研究大多关注 LLM 在软件开发阶段的作用,比如代码生成,忽视了在开发后阶段(post-development)的工作,而这个阶段往往直接关乎用户的体验。文章推出了 OpenRCA,包含一个benchmark数据集和一个评估框架,用于衡量 LLM 在定位软件故障根因上的能力。
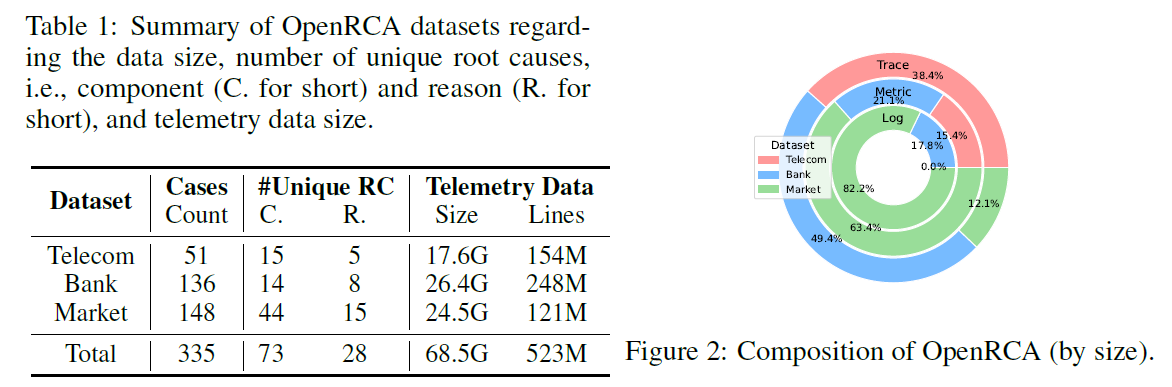
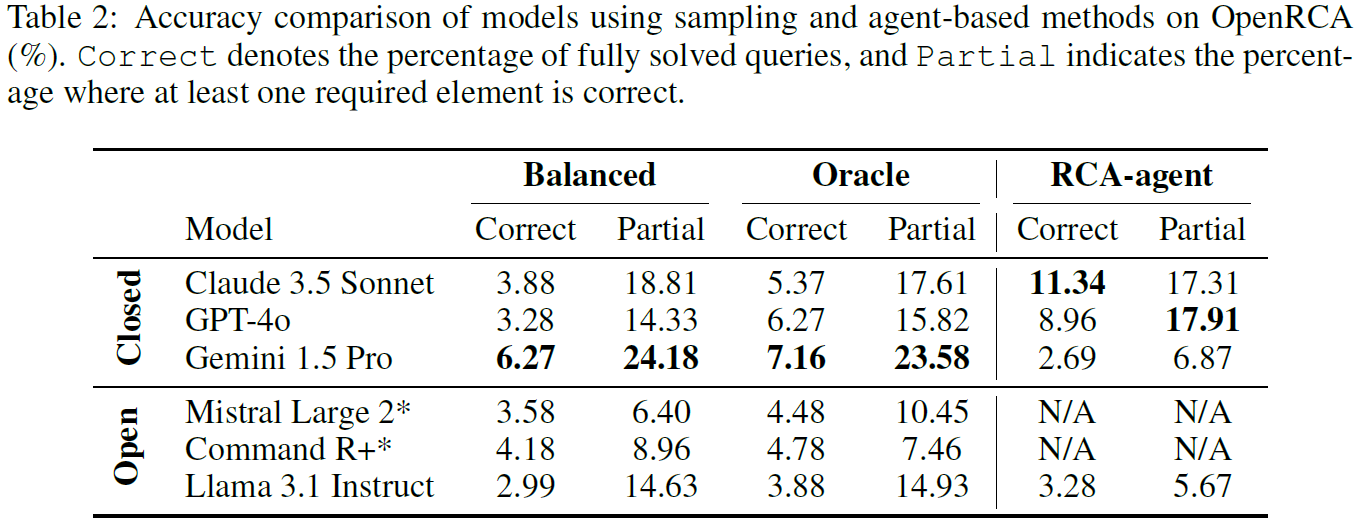
OpenRCA 包含 335 个真实场景的 failure case,这些 failure case 来自 3 个企业系统,并附带有 68 GB 的多模态遥测数据(metric,trace,log)。LLM 需要接收给定的 failure case 和对应的遥测数据,加以推理,然后识别出故障根因。实验表明,即使是表现最好的 LLM,也只能解决 11.34% 的 failure case。
背景
对于在线系统的软件维护和debug是非常困难的,虽然有大量工作在致力于通过多模态遥测数据来定位故障根因(RCA),但是这个任务仍然具有较大的挑战性,因为线上软件系统有着难以估计的复杂性。
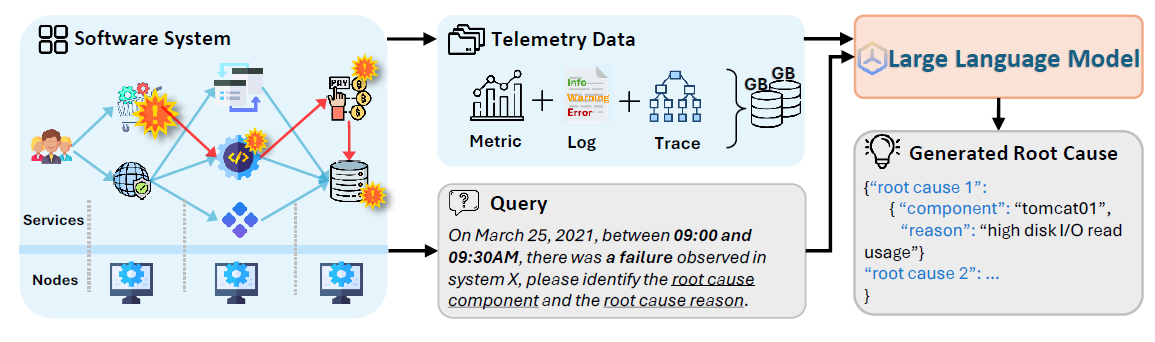
LLM 是否能胜任 RCA 工作呢?文章为此提出了一个 benchmark 数据集:OpenRCA, 包含 335 个真实场景的 failure case,这些 failure case 来自 3 个企业系统,并附带有 68 GB 的多模态遥测数据(metric,trace,log)。如上图所示,对于每个 failure case 以及一个对应的自然语言的 query, LLM 需要分析大佬的多模态遥测数据,理解系统之间的内在关联,并推理出可能的故障根因。
OpenRCA
特点
OpenRCA 包含了大佬真实场景的 failure case,有如下特点:
- 真实场景
- 目标驱动的任务设计(不再是简单定位一个故障组件,而是通过自然语言表达任务)
- 多模态异构遥测数据
- 完整的 LLM 评估
- 支持新标签和新遥测数据的集成
问题建模
故障根因有三个元素:根因组件(originating component)、开始时间(start time)、故障原因(failure reason)。每个人的目标可能不一样,所以需要对上述元素进行组合得到目标。
OpenRCA 定义了7个目标,是3个元素的组合(\(C_3^1+C_3^2+C_3^3\), LLM 的输出应该是7种目标中的一种
2
3
4
5
6
7
8
9
10
11
"input": [
"time range: {time_period}",
"number of failures: {num}"
],
"output": [
"root cause component: {component}",
"root cause occurrence time: {datetime}",
"root cause reason: {reason}"
]
}
评估:对于每个 failure case,如果输出的内容符合实际,则加一分,否则不得分。这里要避免文本表达差异而导致的评估错误,prompt 中预先提供了所有可能的故障原因和原始组件。最终计算 \(accuracy\) ,是所有分数的均值。
1 | { |
数据集构成
OpenRCA 使用的数据集均来自历年的 AIOps 大赛,由于脏数据较多、某些故障标签缺乏(failure reason)等问题,首先采用四步处理方式预处理:

- System Selection: 历年数据集中有些系统因为数据和标签不完备被淘汰,选用满足要求的3个系统
- Data Balancing: 系统之间数据规模差距太大,对大数据量系统进行下采样
- Data Calibration: 规范命名以及人工筛选 failure case
- Query Synthesis: 3个元素组合而成7个目标
最终数据集组成如下:
RCA-Agent
为了解决 OpenRCA 中的任务,首先要面对两个挑战
第一个挑战是如何处理超大规模的遥测数据
直观的解决方法是将所有遥测数据整合为一个 chunk,但是低效且开销巨大的;另一个方法是采样一个遥测数据的子集,但是有丢失关键信息的风险
第二个挑战是遥测数据不是自然语言, LLM 可能无法有效处理:
可选的处理方法是先对所有遥测数据进行代码处理,然后提取关键信息到 LLM
针对上述挑战,文章也提出了一个多智能体的解决方案(RCA-Agent),RCA-Agent 包含两个 LLM 智能体(Controller 和 Executor)

Controller:负责整个流程的调度,指导 LLM 按照 anomaly detection -> fault identification -> root cause localization 进行诊断;指导 LLM 按照 metric -> trace -> log 的顺序进行分析
Executor:在 Controller 的指导下写 Python 代码、执行代码、返回结果给 Controller。由两部分组成
- code generator: 生成 Python 代码
- code executor: 有个 Python kernel 负责执行
RCA-Agent 工作流:
- Controller 指示 Executor 加载遥测数据(Executor 自己生成并执行代码)
- Executor 返回结果给 Controller
- Controller 分析决策并决定下一个动作
- Controller 和 Executor 不断交互直到最终结果给出
实验
之前提到不可能把所有的遥测数据都输入到 LLM,所以只能用采样来减轻负担,比如只取用每分钟的第一条记录,此外,进一步引入了两个 KPIs 采样方式作为 RCA-Agent 的对比:
- Oracle Sampling:工程师选出最有价值的 KPIs
- Balanced Sampling:随机采样与 Oracle Sampling 同等数量的 KPIs
文章比较了现有的开源模型在 OpenRCA 上的表现
Prompt
这里附上 RCA-Agent 细节和主要 Prompt
Controller System Prompt 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37You are the Administrator of a DevOps Assistant system for failure
diagnosis. To solve each given issue, you should iteratively instruct
an Executor to write and execute Python code for data analysis on
telemetry files of target system. By analyzing the execution results,
you should approximate the answer step-by-step.
There is some domain knowledge for you:
{BACKGROUND KNOWLEDGE OF SYSTEM}
## RULES OF FAILURE DIAGNOSIS:
What you SHOULD do:
1. **Follow the workflow of ‘preprocess -> anomaly detection -> fault
identification -> root cause localization‘ for failure diagnosis.**
...
What you SHOULD NOT do:
1. DO NOT include any programming language in your response.
...
The issue you are going to solve is:
{PROBLEM TO SOLVE}
Solve the issue step-by-step. In each step, your response should follow
the JSON format below:
{
"analysis": (Your analysis of the code execution result from Executor
in the last step, with detailed reasoning of ’what have been done’
and ’what can be derived’. Respond ’None’ if it is the first step
.),
"completed": ("True" if you believe the issue is resolved, and an
answer can be derived in the ’instruction’ field. Otherwise "False
"),
"instruction": (Your instruction for the Executor to perform via code
execution in the next step. Do not involve complex multi-step
instruction. Keep your instruction atomic, with clear request of ’ what to do’ and ’how to do’. Respond a summary by yourself if you believe the issue is resolved.)
}
Let’s begin.
Executor System Prompt 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17You are a DevOps assistant for writing Python code to answer DevOps
questions. For each question, you need to write Python code to solve
it by retrieving and processing telemetry data of the target system.
Your generated Python code will be automatically submitted to a
IPython Kernel. The execution result output in IPython Kernel will be
used as the answer to the question.
## RULES OF PYTHON CODE WRITING:
1. Reuse variables as much as possible for execution efficiency since the
IPython Kernel is stateful, i.e., variables define in previous steps
can be used in subsequent steps.
...
There is some domain knowledge for you:
{BACKGROUND KNOWLEDGE OF SYSTEM}
Your response should follow the Python block format below:
‘‘‘python
(YOUR CODE HERE)
‘‘‘
Summary Prompt。Controller 认为任务已经完成,则这个
Prompt将会发给 Controller 1
2
3
4
5
6
7
8
9
10
11Now, you have decided to finish your reasoning process. You should now
provide the final answer to the issue. The candidates of possible
root cause components and reasons are provided to you. The root cause
components and reasons must be selected from the provided candidates
.
{BACKGROUND KNOWLEDGE OF SYSTEM}
Recall the issue is: {PROBLEM TO SOLVE}
Please first review your previous reasoning process to infer an exact
answer of the issue. Then, summarize your final answer of the root
causes using the following JSON format at the end of your response:
{OPENRCA ANSWER FORMAT}