题目:TRACEZIP: Efficient Distributed Tracing via Trace Compression
来源:FSE 2025
作者:中山大学
摘要
分布式追踪(distributed tracing)是监控微服务系统内部执行逻辑的重要手段,但同时也给系统带来了巨大的计算和存储的负担。现有的方式是通过采样(sampling)来捕获更少的trace,然而,现有的两种 sampling 方式面临采样质量和系统负载的抉择:
- head-based sampling:无差别选择某些请求进行追踪,容易遗漏关键数据
- tail-based sampling:追踪所有请求,存储 edge-case traces,但 trace 收集和传输时的负载仍然很大
文章从另一个角度触发,提出了 TraceZip,通过 trace compression 来减少各阶段的负载。核心思想是 trace 数据结构之间存在显著的冗余,导致微服务和后端之间大量相同数据的重复传输。文章设计了一种新的数据结构 Span Retrival Tree(SRT),能够持续压缩这种冗余,以轻量化的方式传输 traces;在后端,完整的 traces 可以基于先前的通用数据重建。TraceZip 已经在 OpenTelemetry Collector 中实现,能够与现有的 tracing API 兼容
背景
trace 是理解微服务系统行为,诊断微服务故障的重要工具。在生产环境中,捕获所有请求的 traces 会造成显著的负载,这些开销来自于 trace 的生产、收集和存储。为了减少负担,通过会对 trace 进行采样。head-based sampling 在请求执行前随机选择一定比例的请求进行追踪并产生 traces,极大的减少了trace 的生产、收集和存储的开销,但是容易无差别遗漏一些值得关注的 traces,比如异常行为形成的 edge-case traces(e.g., 高延时)。tail-based sampling 追踪所有的 traces,但是会在后端根据某些属性选择哪些 traces 进行保留。由于 traces 的价值具有不可预测性,很难完全覆盖测试和故障诊断所需的所有 traces。同时 tail-based sampling 的计算和传输开销依旧很大
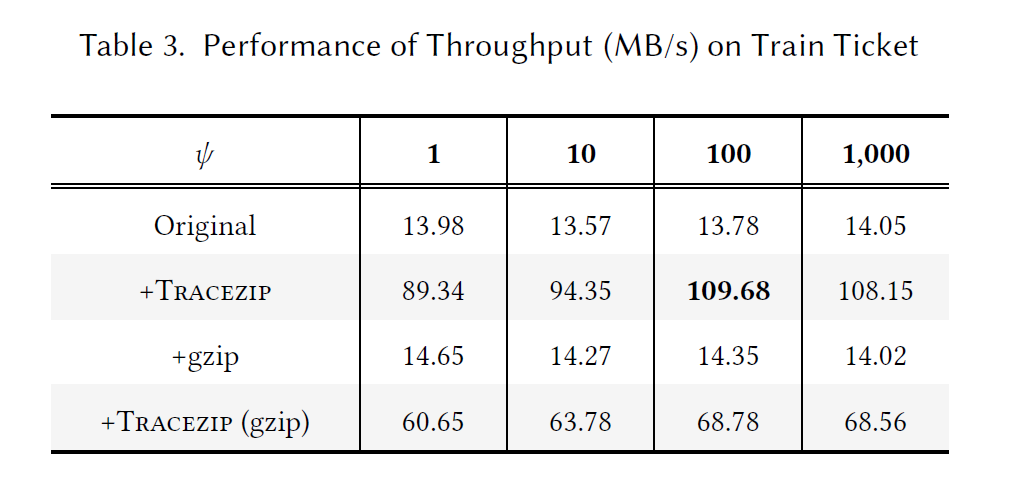
因此,文章提出了一种针对 trace 的压缩方法 TraceZip,在微服务端用一种更简洁的数据结构压缩 trace 中的 span,在后端能够无缝还原为原始的 span,这样能够大幅减少传输中的开销。而传统的日志压缩无法适用于 trace 这种流式数据
动机
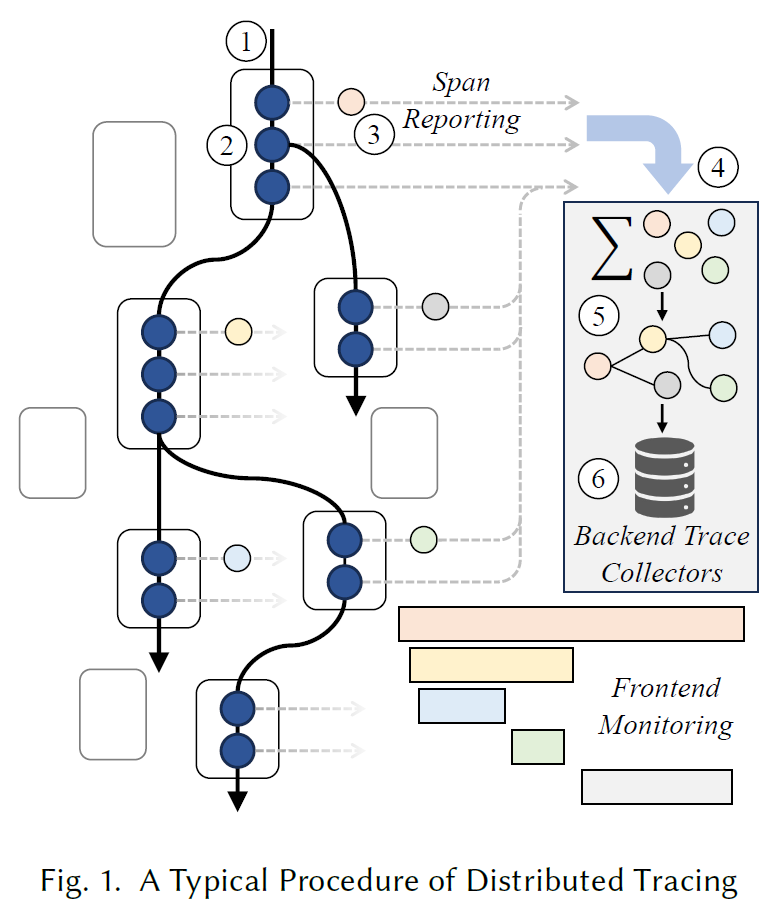
文章部署了 Train Ticket 系统,并通过 OpenTelemetry 提供的无侵入方式进行监控,收集了大约 40 GB 的 traces。文章通过每个微服务产生的重复 key-value (KV) 对的比例来量化 trace 的冗余。对于每个 KV 对,冗余比即为它在所有 KV 对出现次数的比例,比如一个 trace 数据集有 100个 KV 对,如果有两个 KV 对分别出现 1 次 和 10 次,则冗余比为 1% 和 10%。
通过实证分析,左图是 Train Ticket 常规微服务,右图是常见的中间件,文章得到两个结论:
- Trace 是高度冗余的。文章将冗余次数阈值设置为1000,计算>1000和<1000的 KV对在每个服务中的比例(这里有点怪,从冗余比计算变成了冗余次数)。从图2的第一张图可以看出,微服务中大概 70% 的 KV 对是高度冗余的;从图2的第二张图可以看出,除了个别组件(Kafka),因为 kafka 的 traces 包含了消息队列中的数据信息,有随机性。这是因为服务经常参与标准交互,生成的trace具有相似的模式。通过在微服务端捕获 span 生成时的冗余,我们可以提前消除后端已经存在的重复数据的传输。后端可以根据冗余模式轻松重建完整的 span
- 属性之间存在结构化冗余。OpenTelemetry 为 span 的通用属性(Key)提供了标准的命名规范,用于保持跨语言的一致性,这个命名机制也存在一些冗余,比如 network.local.address, network.local.port, network.peer.address 有一些共同的单词;值(Value)也存在一些冗余,比如 Java Exception has java.io.IIOException, java.io.EOFException 等, 通过移除这些细粒度的冗余,也可以进一步减少 span 传输的负载
方法
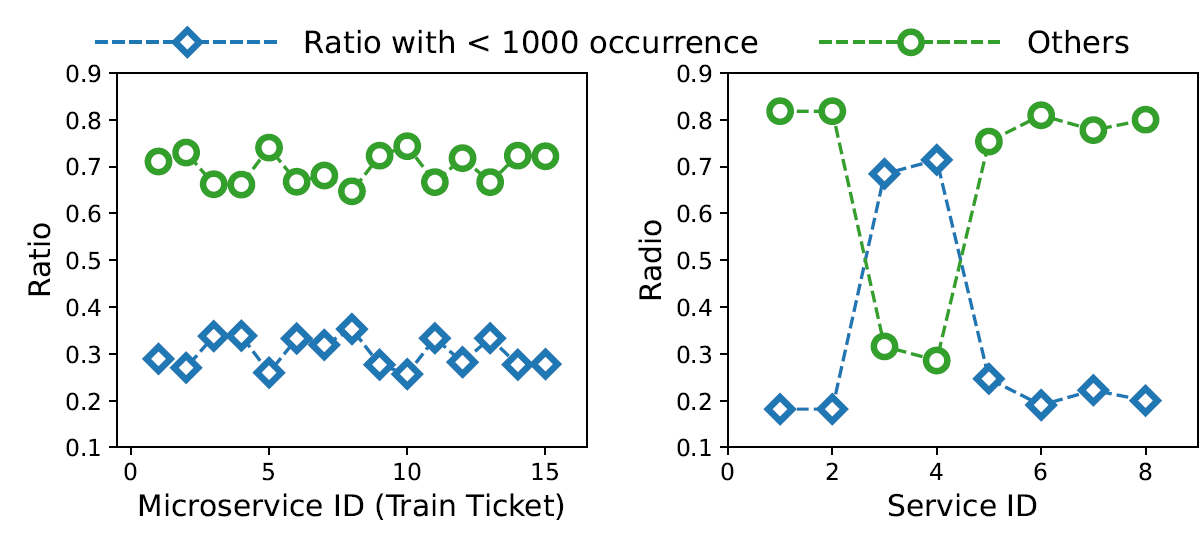
TraceZip 架构图如下所示,主要是加了两个模块 compression 和 decompression
- compression:在微服务端,维护两个数据结构:Span Retrieval Tree (SRT) 和一个字典,持续捕获和压缩 spans 的冗余。如果 span 携带了新的冗余信息,则会无缝集成到上述数据结构中。
- decompression:在后端 collector 入口处,spans 基于 SRT 和字典进行重建。
- differential update mechanism:微服务端和后端的 SRT 和字典需要持续同步,这个机制会同步两侧数据结构的增量变化,确保低开销的高效协同
Span 格式
Trace 是树状结构,Span 是树中的节点。Span 本身是一个 JSON 结构的 KV 对集合,键是 String 类型,而值可以是原始数据类型(String, number, boolean, null),也可以是结构化类型(KV字典,array),为了对齐现有框架,一般包含以下字段:
- name,
- parentSpanId,
- Start and End Timestamps,
- Span Context (the context of the span including the trace ID, the span ID, etc.),
- Attributes,
- Span Events
文章在这里有个前提,就是一个操作的 Span 结构不会发生变化,也就是说某个操作生成的 所有 spans 的 Keys 是相同的,只有 Values 会变化
Span 压缩和解压
Span 的直观压缩方式就是使用字典,将每个独特的 KV 对赋予并替换为对应的独特 ID。但这些 KV 对之间还存在细粒度的冗余。除此之外,如果大量 Span 共享同一套 KV 对组合,就可以用一个 ID 来表示这个组合,进一步减少冗余
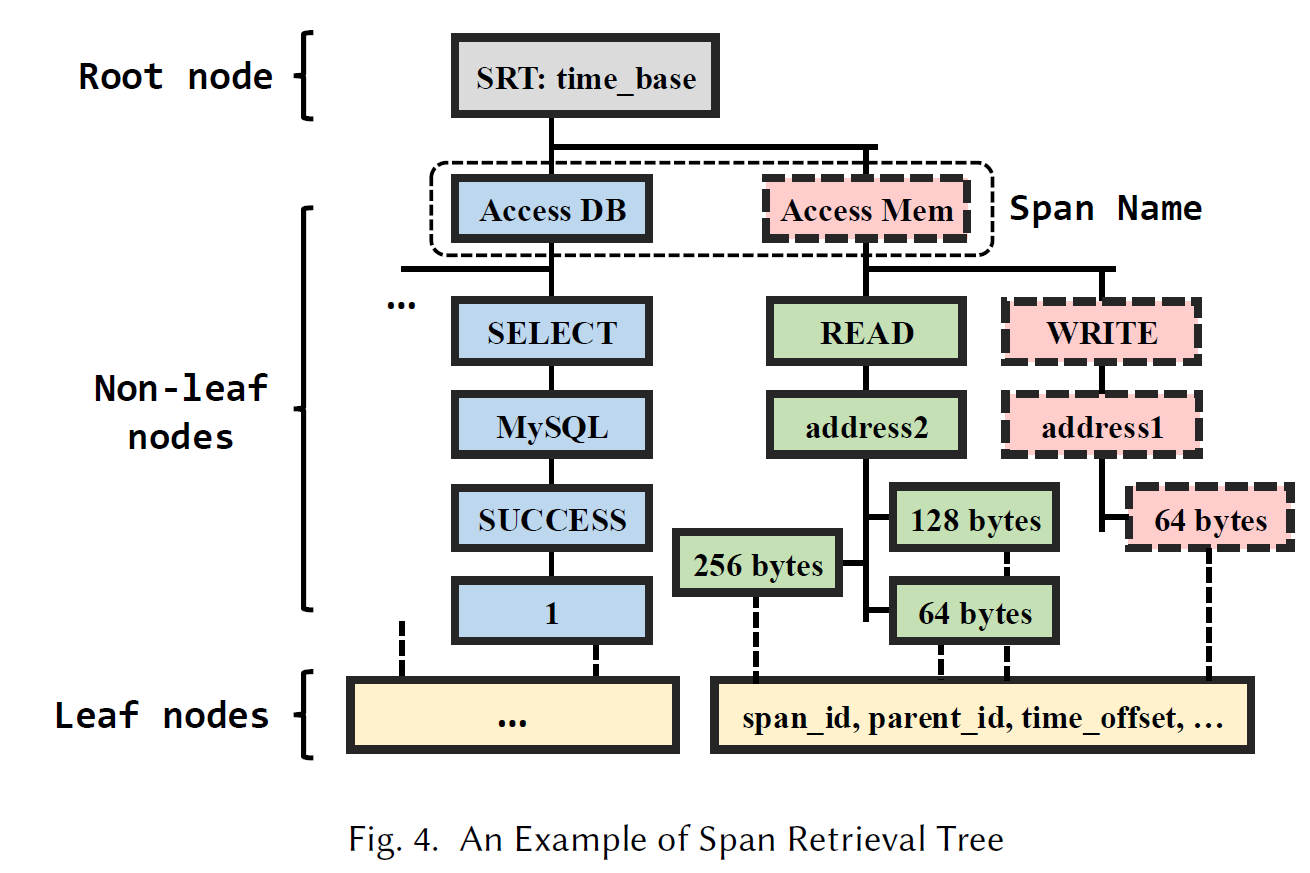
如图所示,文章提出了一种 SRT 的多叉树来减少冗余,其中有三种节点:
- root:存储一个基础时间,可以让 leaf 只存时间偏移
- non-leaf:存有较多重复的 Value,比如 name 和 status 的 Value 只有几种,则把这些 Value 存到 non-leaf 中
- leaf:只存 Value 可选数量太多的 Key,比如 SpanId,time_offset 之类
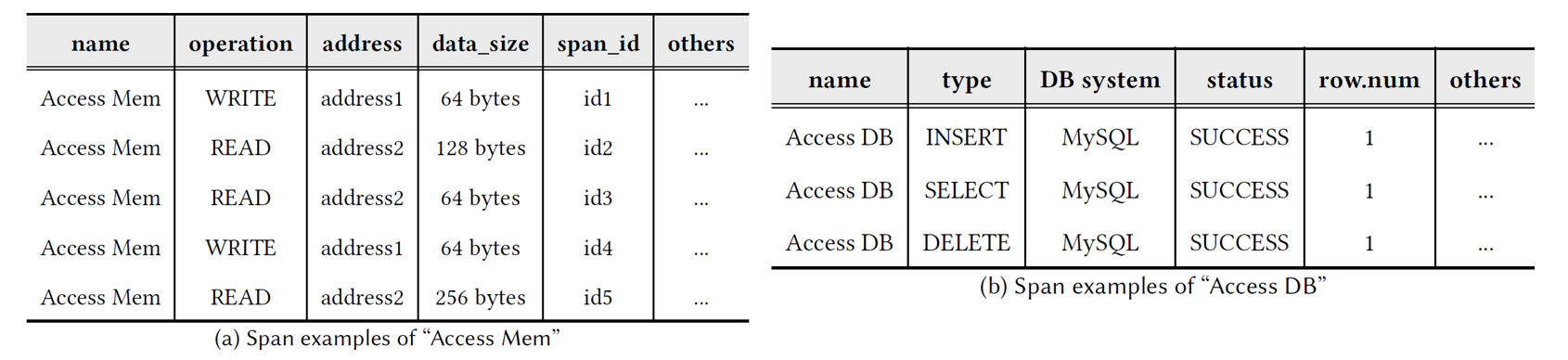
比如 Fig.4 的 SRT 实际上就是由上述两个表格演变来的,每个 span 都可以看作从 root 节点到 leaf 节点的一条路径。演变算法如下所示:

- 接收一个 span 数据流,并处理每一个span
- 如果 span 的 name 不存在于 SRT 中(根节点的子节点,level=1),则将这个 span 的所有 values 串成一条路径,放到 SRT 中。
- 比如 Table 1-(a) 的 span 可以表示为 Access Mem \(\to\) WRITE \(\to\) address1 \(\to\) 64 bytes \(\to\) id1
- 如果 span 的 name 存在于 SRT 中,则从 SRT 中从上到下逐层检验 span 的所有 KV 对是否存在于 SRT 中
- 如果不存在,则需要将新 Value 作为新分支加进 SRT
- 比如 READ \(\to\) address2 \(\to\) 128 bytes \(\to\) id2 将作为新分支加入到 Access Mem 下
- 一旦有新分支加入(即执行了步骤3),则需要检验 SRT 各层的值个数,如果超过阈值 𝜓,则这一层对应的 Key 将会被移到 leaf
- 比如 id 那一层有太多值,则移到 leaf
- 对于某些值是 KV 字典这种复合结构的,则按照如下案例处理:
2
3
4
5
6
7
8
9
10
11
“attributes”: {
“ip”: “172.17.0.1”,
“port”: 26040
}
}
>------------------------------------------
{
“attributes-ip”: “172.17.0.1”,
“attributes-port”: 26040
}- 此时只需要 Span 在 SRT 中的路径(可以用路径ID表示)和 leaf 中 key 对应的值就可以还原出 Span 了
SRT 内存的优化
虽然 SRT 已经极大节省了传输成本,但仍存在较大的空间复杂度,因为 SRT 的潜在增长空间太大,所以文章进行了进一步的优化
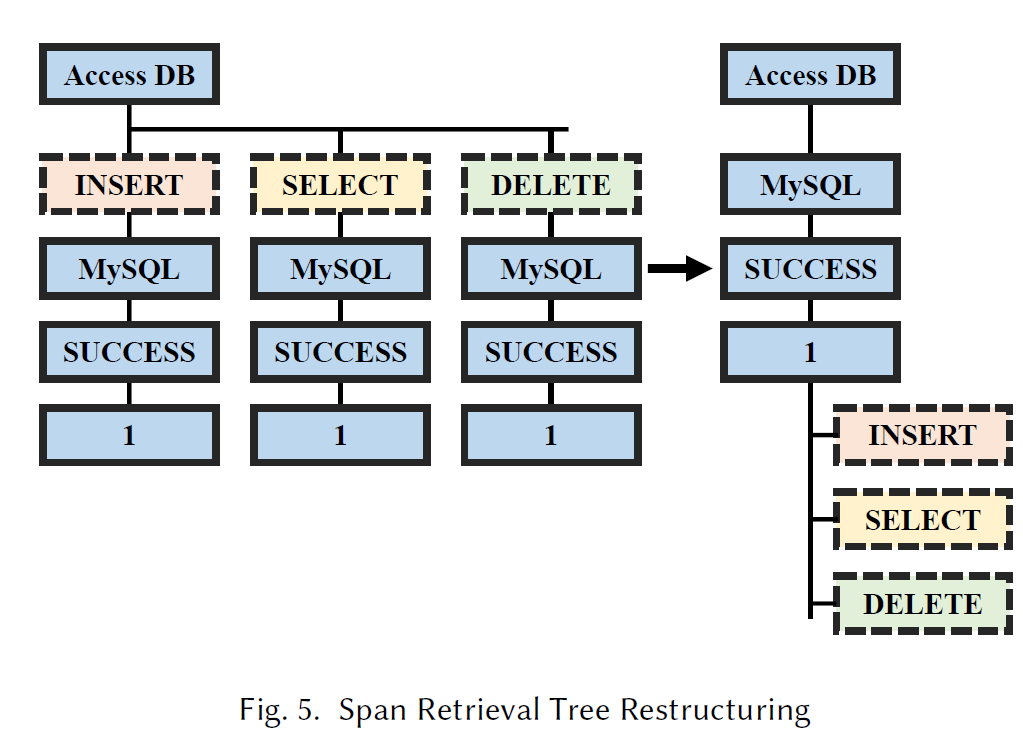
- SRT 重建: Fig.5 是从 Table1.(b) 中建立来的 SRT,可以看到,如果 key 的顺序不当,会造成大量重复。正如上章节算法中第15行,应该在每次 SRT 更新时把 Values 较多的 Key 往下移。
- 基于字典的压缩:Fig.4 中可以看到还是有一些 Value 重复,比如 64 bytes。文章构建了一个字典,这个字典的键是 spans 的 K/V(只包括 SRT 中的内容,不包括 leaf 中 Key 对应的 Value),值是 ID。ID由[0-9a-zA-Z]组成,先从长度为一开始( ’0’ to ’9,’,’A’ to ’Z.’),然后再往上递增长度。只要字典发生更新,就会传输到后端。
SRT 搜索的优化
文章还优化了 SRT 的搜索部分,因为 SRT 涉及频繁的修改,所以最直观的实现方式是链表。然而,链表中各节点不是存储在连续的内存空间中,所以查询时会导致较多的预读失效,影响路径搜索时的效率。
TraceZip 在微服务端维护了一个 hash 表:{path: identifier},当 span 到来时,就不用遍历 SRT 来查询是否存在路径了,直接通过 hash 表获取路径ID
Differential Data Synchronization
为了 Span 压缩和解压,微服务端和后端必须要时刻保持 SRT 和字典的同步。最直观的方式就是发生更改时就将 SRT 和字典发向后端,但有的时候更改往往是一小段,如果将整个数据都发向后端,就会造成额外的网络开销,甚至会阻塞解压操作。
TraceZip 的后端,也就是 trace 的接收器,不再维护一个与微服务端一致的 SRT,转而维护了一个 hash 表 {identifier: path},这样只需要同步两端的 {path: identifier} 和 {identifier: path},只有路径发生新增或删除时才会同步
- 对于字典的更新,只要发生了更改就会同步到接收器,这里为了保证接收器的数据不过时,用了 OpenTelemetry Collector 的批处理功能,在压缩缓冲区中的Span后,将确保在发布数据之前 SRT 和字典已经与接收方同步。
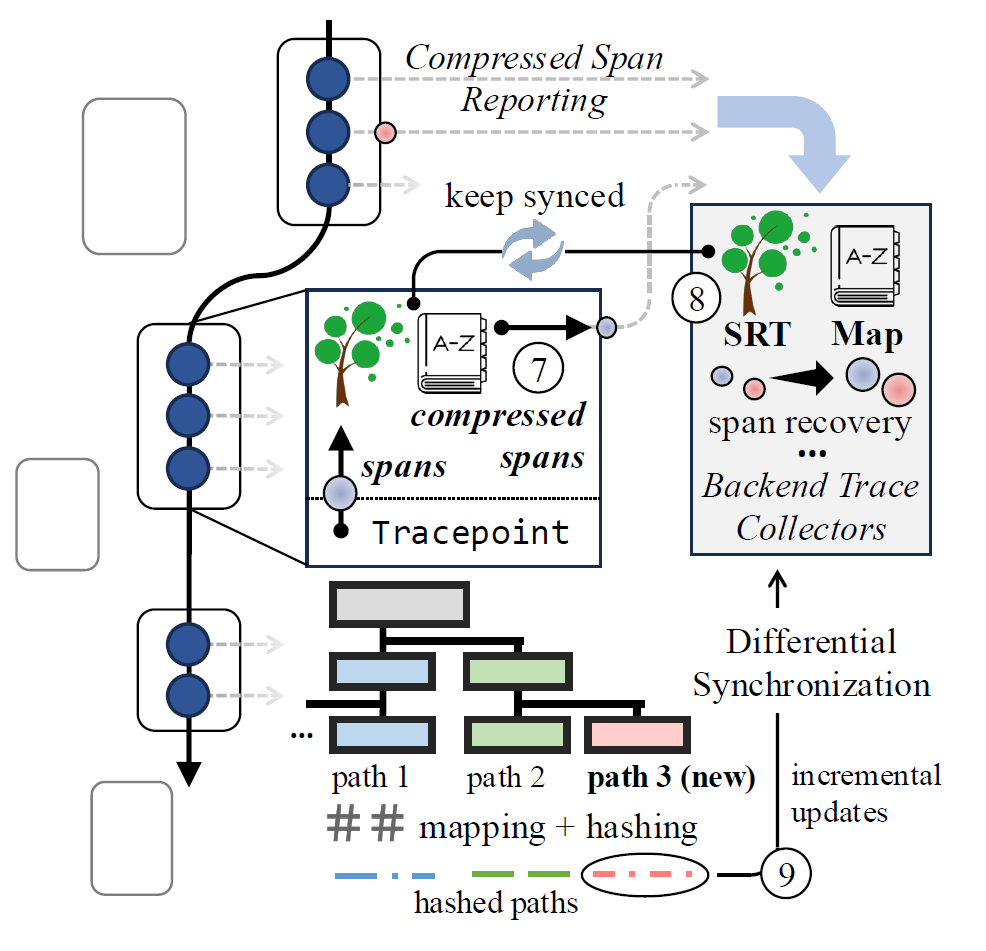
实验
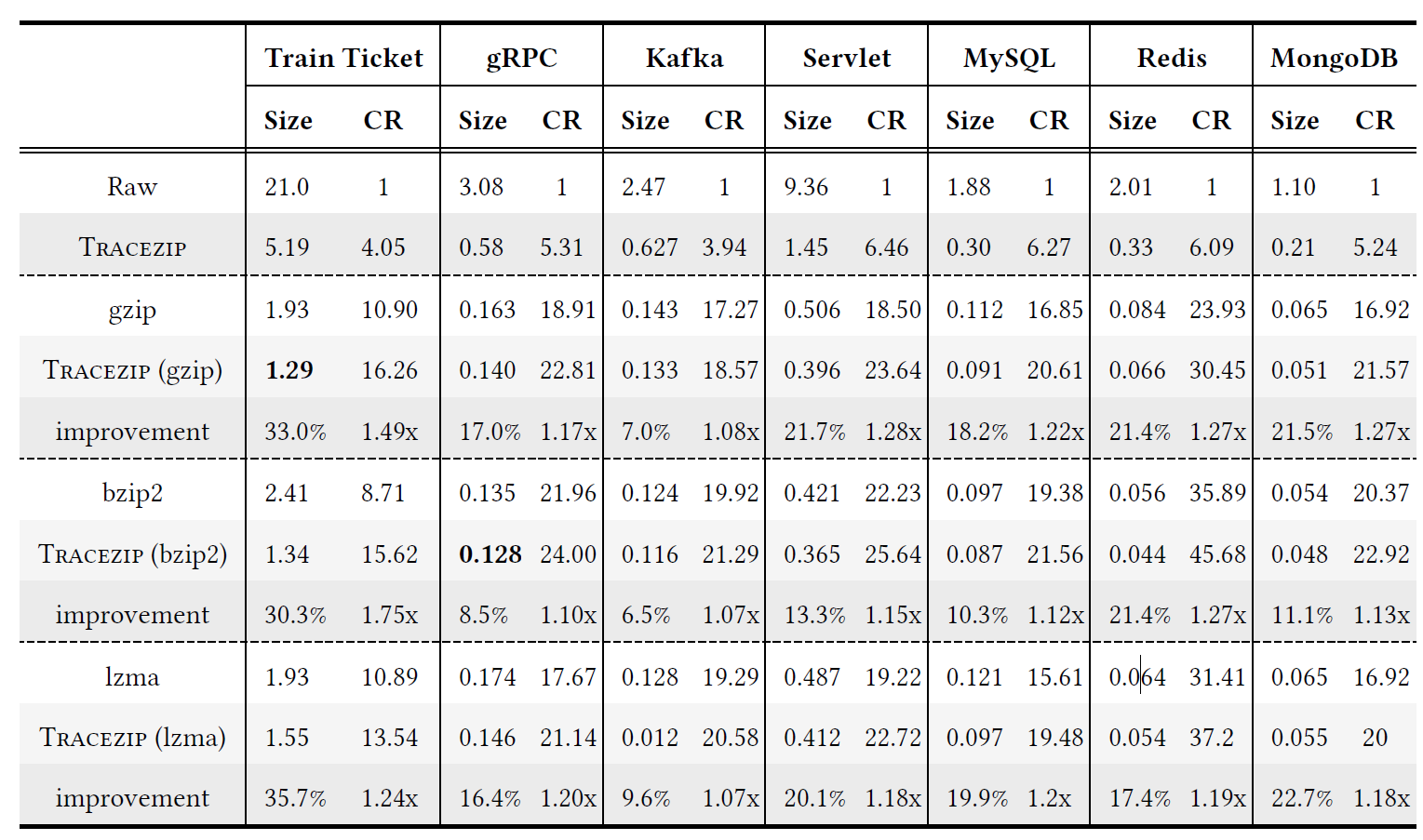
比较的指标是压缩中常用的压缩率: \[ CR=\frac{Original File Size}{Compressed File Size} \]
对比方法采用的是常见的压缩算法:gzip, bzip2, lzma.
同时探究了不同压缩算法的吞吐量 (MB/s)