题目:The Vision of Autonomic Computing: Can LLMs Make It a Reality
来源:arxiv 2024
作者:南京大学,微软
摘要
智能运维的最终梦想是想让微服务系统能够自主诊断和恢复,这篇文章向这个方向努力探出了一步。文章的目标是实现微服务系统的自主计算的愿景(ACV, Vision of Autonomic Computing),大模型的出现让 ACV 的实现出现了可能性。
文章推出了一个基于大模型的分层多智能体架构,用于维护微服务系统的可靠性。其中,高级别群组管理者(high-level group manager)用于接收声明式任务,比如优化延时到200ms以下;低级别自主智能体(low-level autonomic agent)聚焦实施各种具体任务。
为了评估此套自动化系统,文章提出了一种五层分类法,重点关注自优化和自恢复;此外,文章还在 SockShop 中进行了实战演练,通过混沌工程注入故障并观察系统如何自恢复。
背景
自主计算
在智能运维中,自主计算的目标是减少微服务系统维护的复杂性,提升可靠性和性能,之前的 ACV 文章提出了四个自主计算的目标:
- 自配置:可以配置和重配置系统,以满足目标
- 自优化:可以持续监控系统,并找到机会优化系统以提升性能和减少开销
- 自恢复:发生故障时恢复,甚至预测故障
- 自保护:防御恶意进攻和故障传播
现有的自主计算一般采用 MAPE-K 的架构,即 Monitor,Analyze,Plan,Execute,Knowledge Base。有大量工作基于 rule-based 方法,在特定场景下有用,但是在复杂动态的微服务系统中需要作出自适应和上下文感知的决策,rule-based 方法无法做到,所以越来越多的方法采用 AI 来替代。
云原生应用自主管理显得更为困难,因为大多拥有复杂的系统结构,安全和可靠性也存在高要求。虽然有大量工具来帮助管理,比如 Kubernetes 和 Prometheus,但是这些工具都无法将人类意图直接转化为对应的功能,有着极高的学习和操作成本。
随着 LLM 的快速发展,大量研究尝试将 LLM 集成到 Kubernetes 中参与微服务系统的管理,比如 GenKubeSec 和 K8sGPT ,也有些工作将 LLM 集成到智能运维中,但这些工作都无法实现自管理。
方法
方法概述
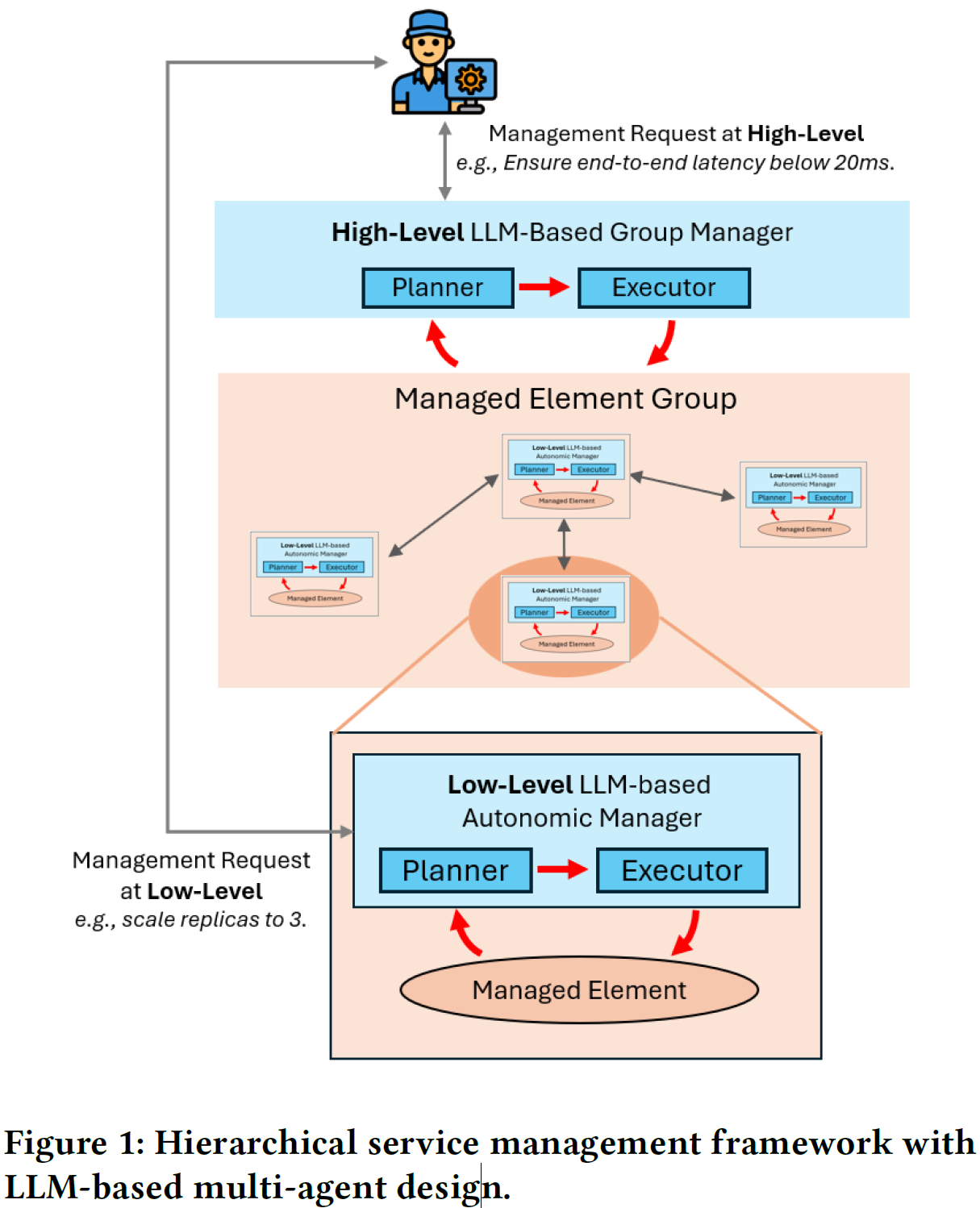
文章提出了一种 ACV 架构, 整体上分为2层:
低级别自主智能体: 用于执行简单的维护代码,充分使用 LLM 的代码生成和执行能力高级别群组管理者: 分解复杂任务为多个 sub-tasks,制定 step-by-step 计划,下发 sub-task 到具体的低级别自主智能体,接收反馈并判断有没有完成目标
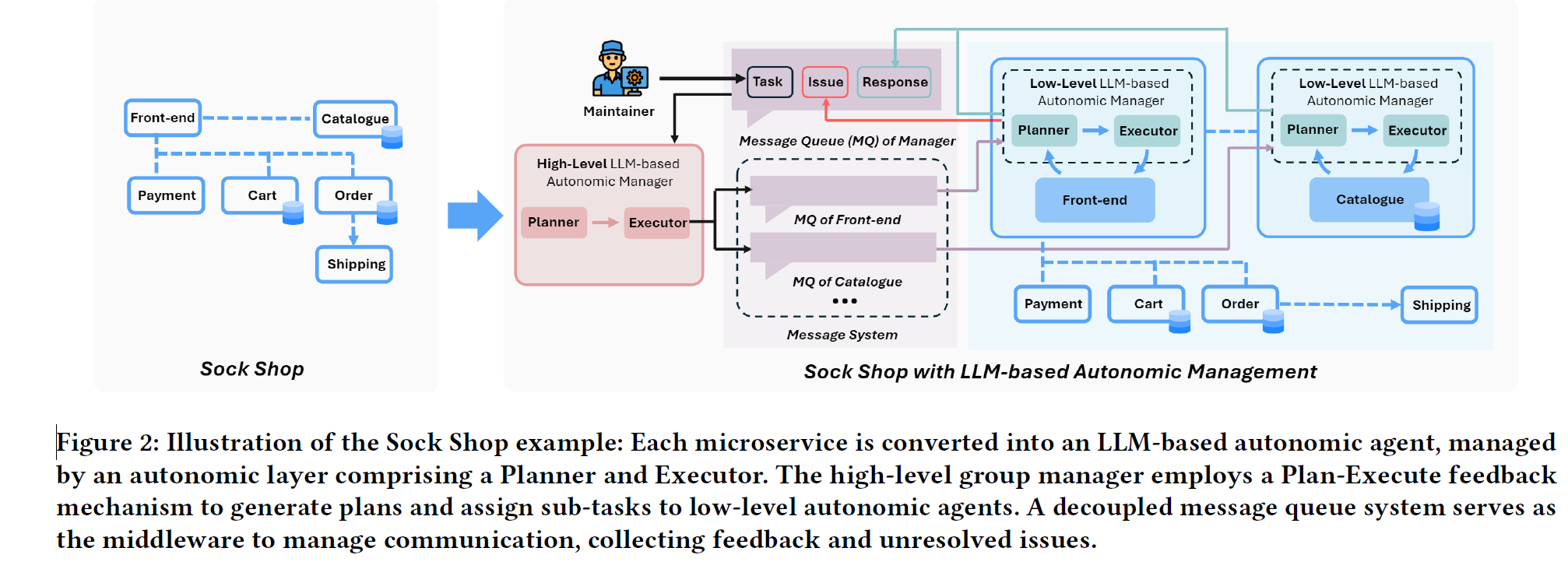
而对于每个智能体的设计,不同于传统的 MAPE-K 架构,基于 LLM 的 ACV 中每个智能体都是由两个模块组成:Planner 和 Executor,Planner 负责制定执行计划(监控、分析),Executor 负责执行具体步骤,并反馈结果给 Planner
三种负载机制
低级别自主智能体独立工作
- 简单的任务(扩容副本到3)可以直接下发到一个低级别自主智能体
高级别群组管理者引导下的多智能体协同
- 复杂的任务(将延时控制到200ms以下),按照如下顺序:分解任务、制定计划、分配任务到低级智能体、接收反馈并调整计划
低级别自主智能体的协同(无高级别群组管理者)
- 如果一个低级别智能体无法处理工作时,可能不经过高级别智能体,直接找另一个低级智能体协同
智能体之间的通信方式是消息队列
SockShop 实施案例
## 实验评估
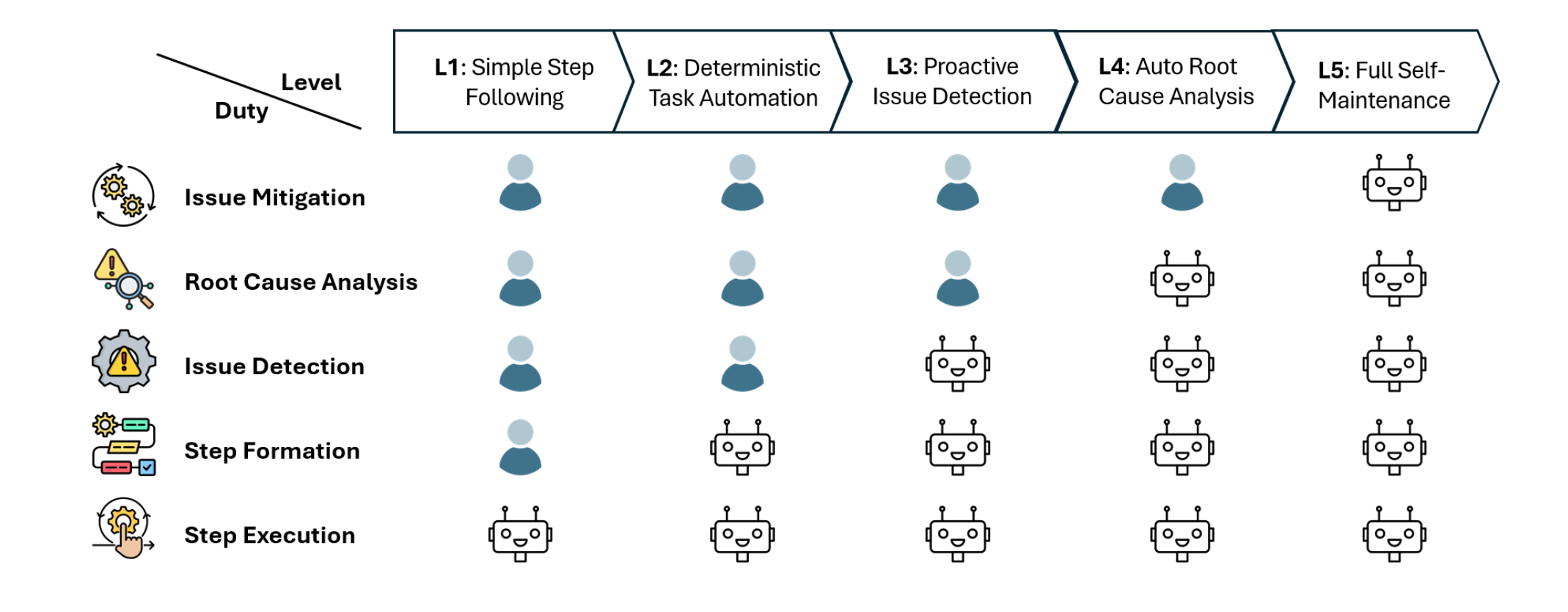
首先文章推出了五层分类法来评估智能体系统的能力:
- L1:智能体是否能选择正确的运维操作指令
- L2:智能体能否有计划能力,将任务分解为多步执行
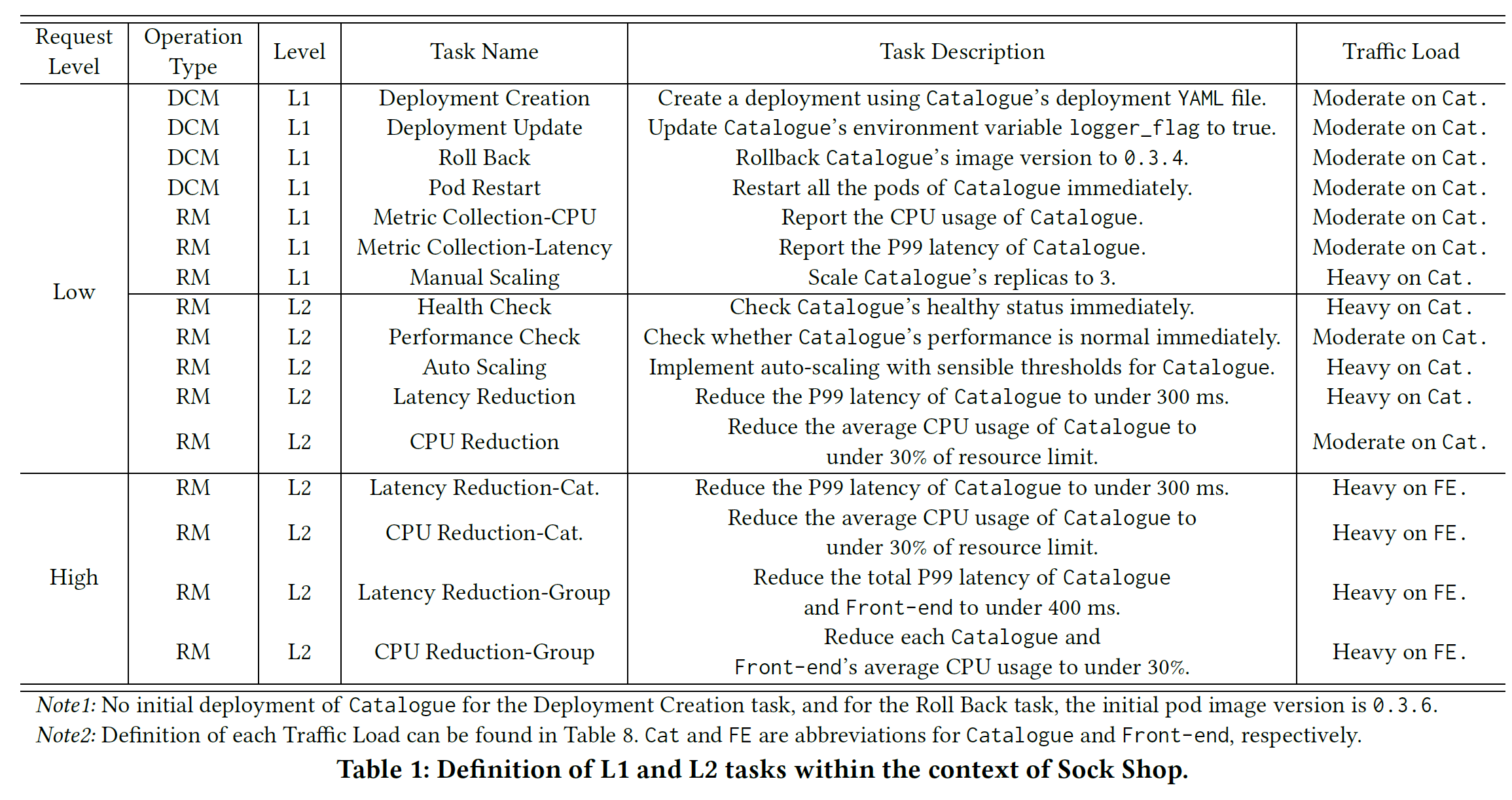
L1 和 L2 针对的都是祈使任务(imperative task),直接表达要做某个具体的任务,智能体只是被动执行。更高级的自主智能体应该能够应对声明式任务(declarative task),即主动采取一些动作来完成目标
如下图所示,文章在自主管理微服务系统中用具体案例表示了剩下的 L3、L4 和 L5
为了评估 ACV 的能力,首先是评估 L1 和 L2,这些测试任务中既包括部署阶段的,也包括运行时的
对于 L3,L4 和 L5,文章在 SockShop 中用混沌工程注入故障,观察故障自愈情况,注入故障包括三类:
- Pod Failure:将 Catalogue 服务的镜像换成一个假的、没有功能的镜像
- CPU Stress:将 Catalogue 的 POD 的 CPU 打到 100%
- Rising Traffic:逐步升高负载,直至无法承受
为了评估故障自愈情况,定义了如下 SLO:
- 所有的服务需要处于 READY 状态
- 所有的服务 CPU 和 内存的使用率需要在 50% 以下
- 所有服务的 P99 延时控制在 200ms 以下
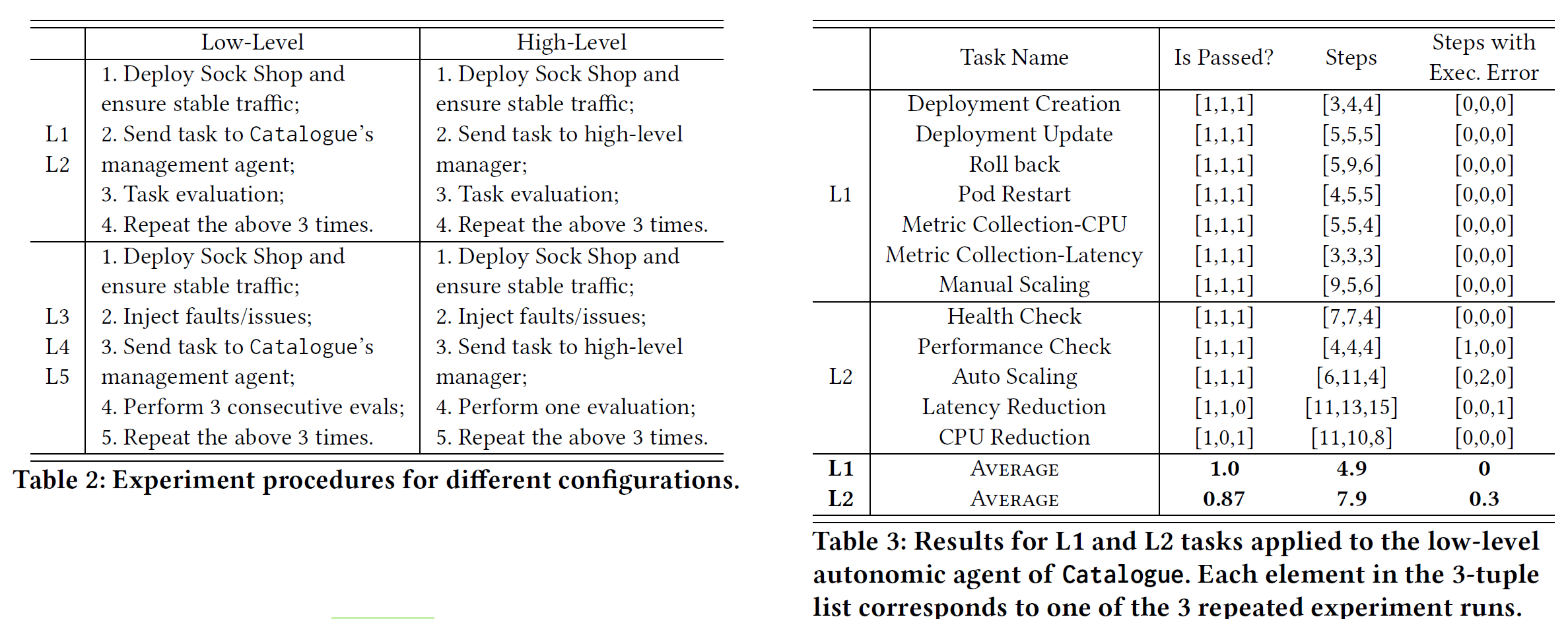
实验流程和实验结果如下,每个实验跑三次:
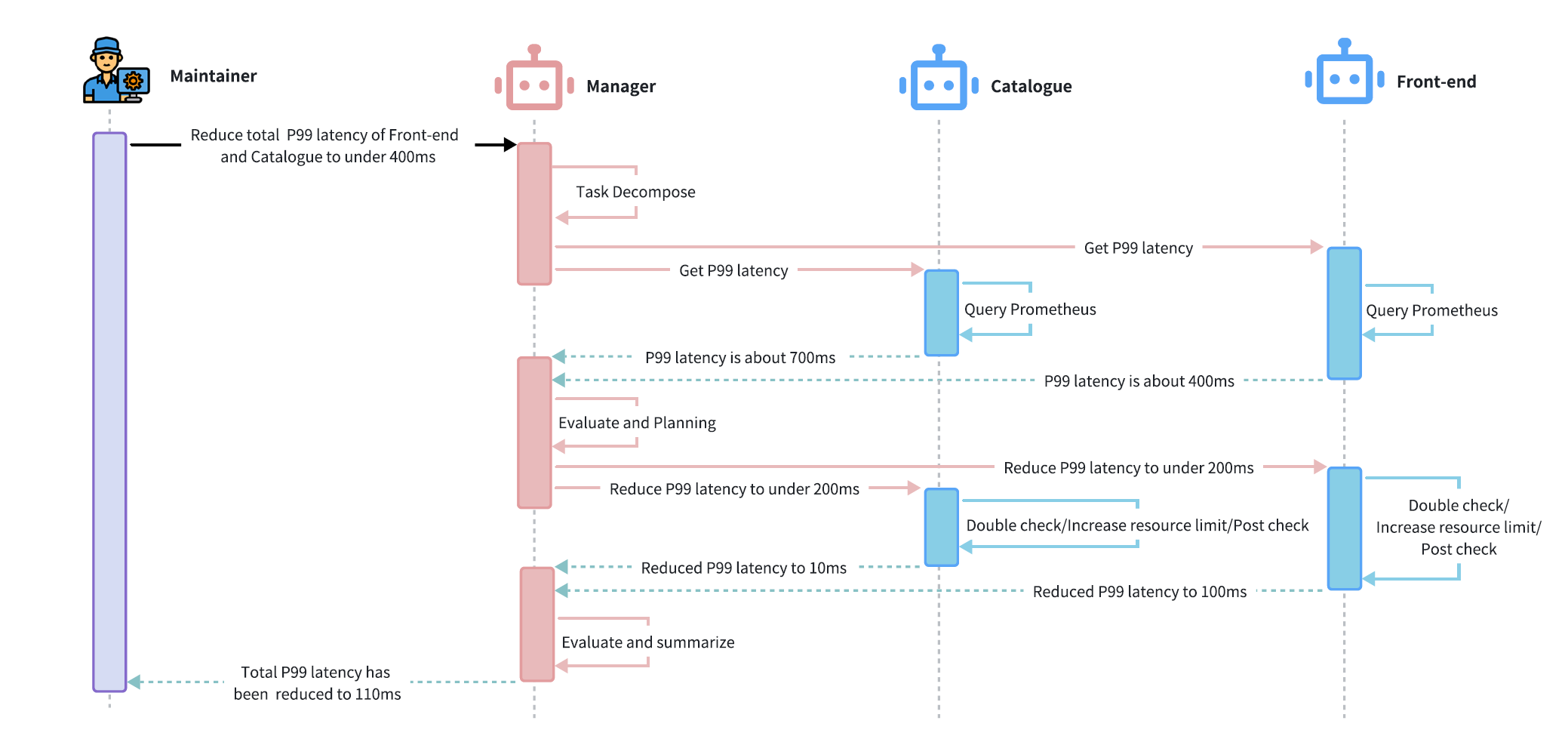
同时文章也给出了一个高级群组智能体规划的复杂任务案例: