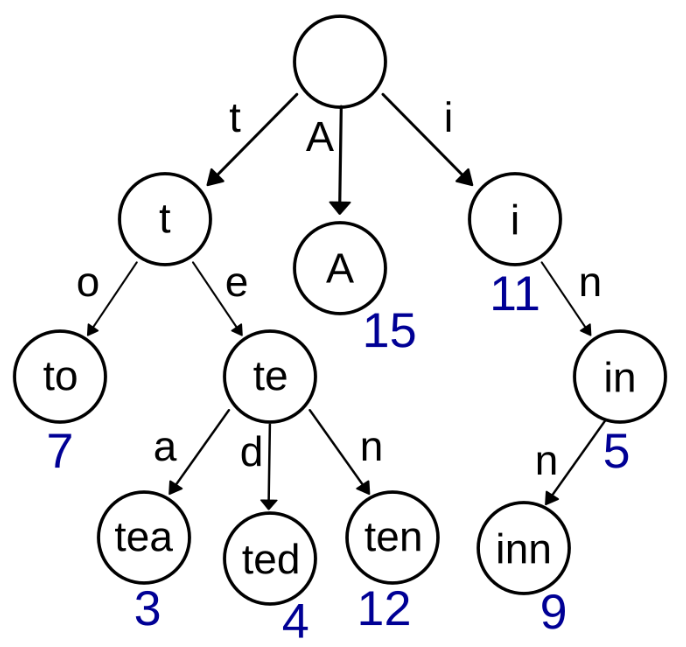
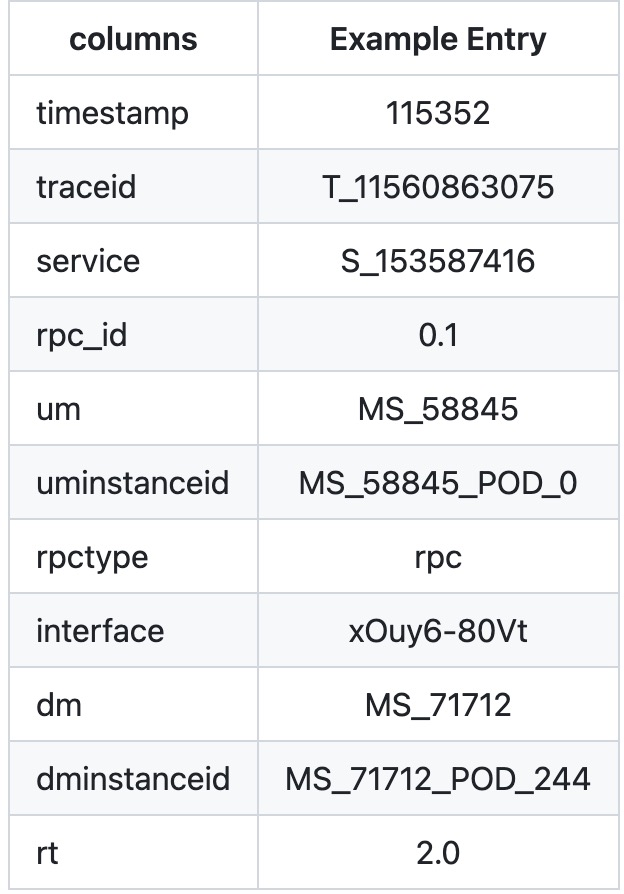
definsert(self, word): """ :type word: str :rtype: None """ cur_node = self.root for c in word: if c in cur_node.keys(): cur_node = cur_node[c] else: cur_node[c]={} cur_node = cur_node[c] cur_node[0]=0# 标记是否截止 # 标记这个cur_node,标注上截止信号,代表这是一个词 cur_node[0]=1
defsearch(self, word): """ :type word: str :rtype: bool """ cur_node = self.root for c in word: if c in cur_node.keys(): cur_node = cur_node[c] else: returnFalse # 判断有没有截止信号 if cur_node[0]==0: returnFalse returnTrue
defstartsWith(self, prefix): """ :type prefix: str :rtype: bool """ cur_node = self.root for c in prefix: if c in cur_node.keys(): cur_node = cur_node[c] else: returnFalse returnTrue trie = Trie() trie.insert("app") trie.insert("apple") trie.insert("beer") trie.insert("add") trie.insert("jam") trie.insert("rental") trie.insert("rental") print(trie.search("apps")) print(trie.startsWith("app")) print(trie.search("app"))
if \(X[i]==Y[j]\), \(dp[i][j] = dp[i-1][j-1] + 1\)
if \(X[i]!=Y[j]\), \(dp[i][j] = max(dp[i-1][j],
dp[i][j-1])\)
python代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution(object): deflongestCommonSubsequence(self, text1, text2): """ :type text1: str :type text2: str :rtype: int """ n, m = len(text1), len(text2) # 多声明一行一列,方便计算dp[1][1] dp = [[0for j in range(m+1)] for i in range(n+1)] for i in range(1, n+1): for j in range(1, m+1): if text1[i-1] == text2[j-1]: dp[i][j] = dp[i-1][j-1] + 1 else: dp[i][j] = max(dp[i-1][j], dp[i][j-1]) return dp[n][m]
classSolution(object): deflongestCommonSubsequence(self, text1, text2): """ :type text1: str :type text2: str :rtype: int """ n, m = len(text1), len(text2) # 多声明一行一列,方便计算dp[1][1] dp = [[0for j in range(m+1)] for i in range(n+1)] for i in range(1, n+1): for j in range(1, m+1): if text1[i-1] == text2[j-1]: dp[i][j] = dp[i-1][j-1] + 1 else: dp[i][j] = max(dp[i-1][j], dp[i][j-1]) # 回溯 i, j = n, m lcs = [] while (i > 0and j > 0): if text1[i-1]==text2[j-1]: lcs.append(text1[i-1]) i-=1 j-=1 else: if dp[i-1][j] > dp[i][j-1]: i-=1 else: j-=1 lcs_str = ''.join(lcs)[::-1]
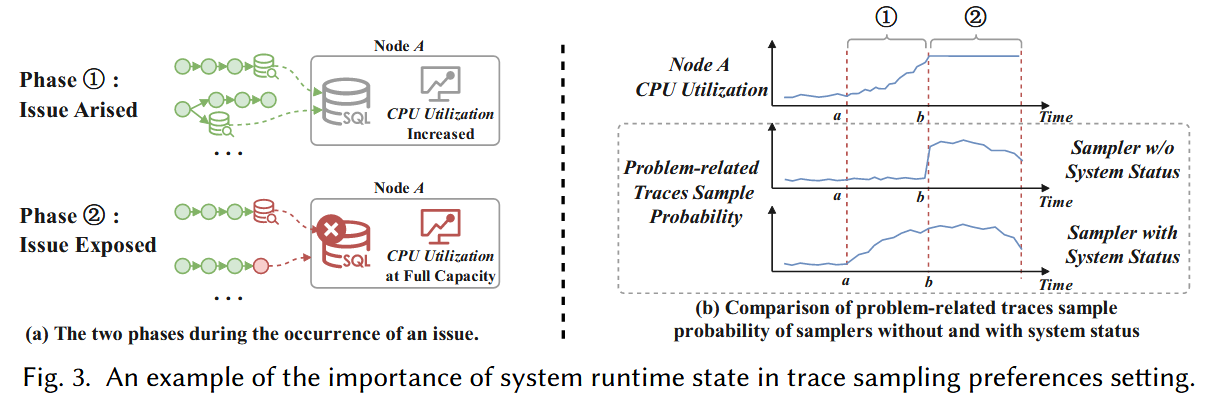
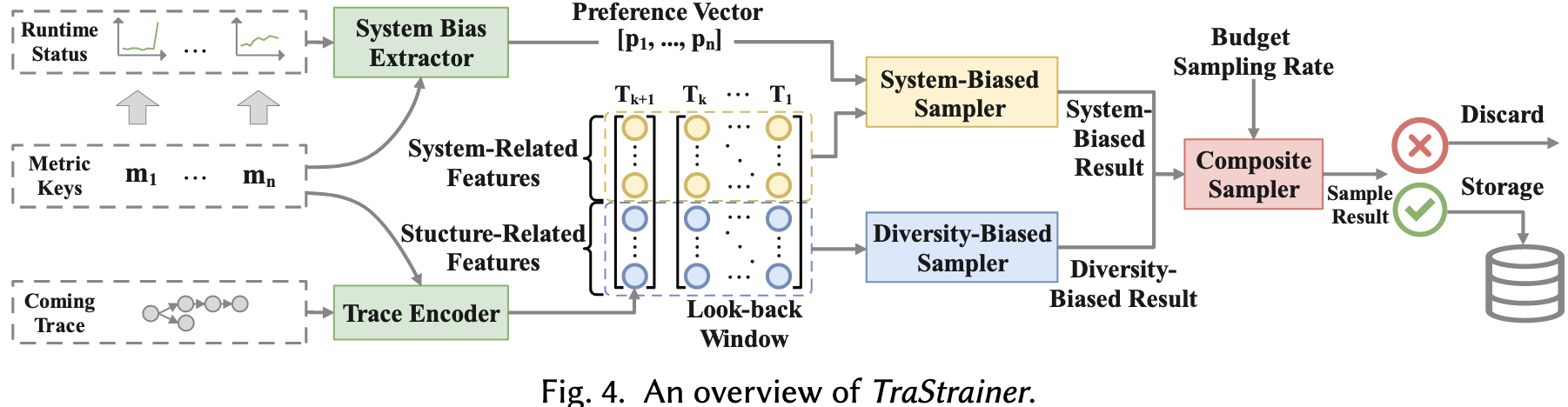
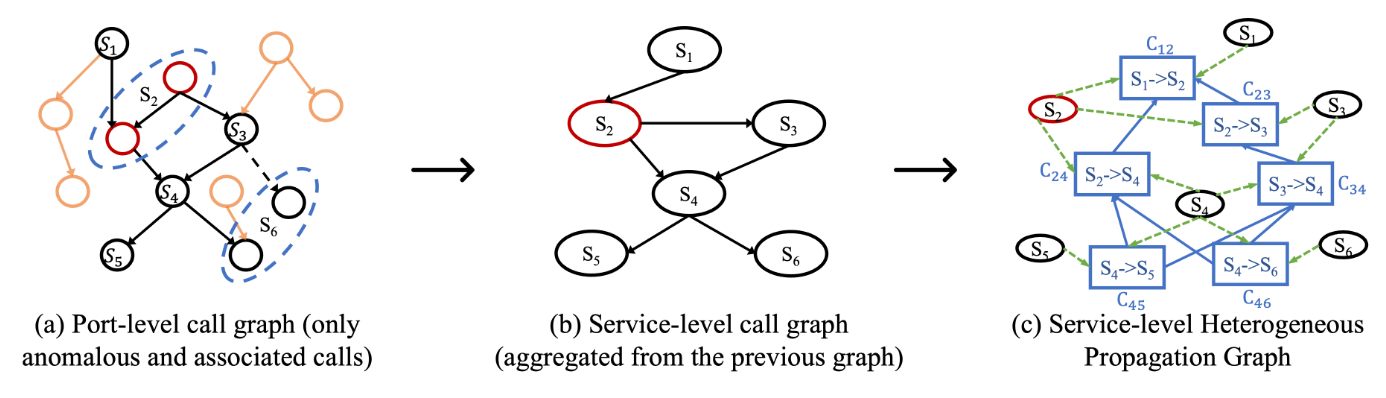
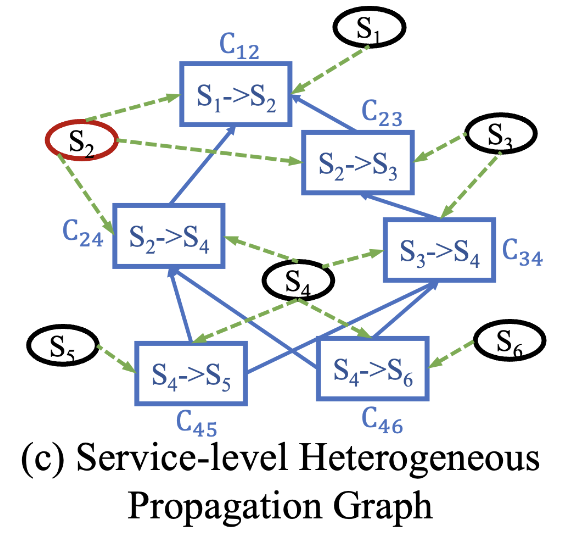
结合 system runtime state
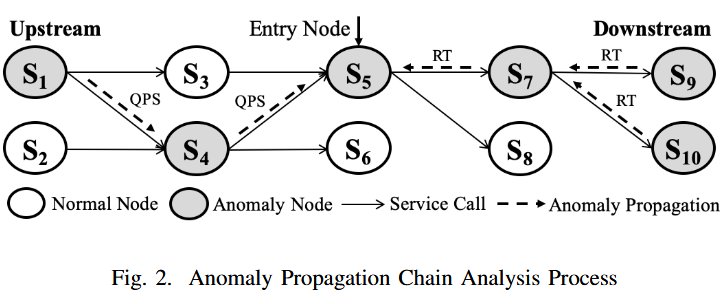
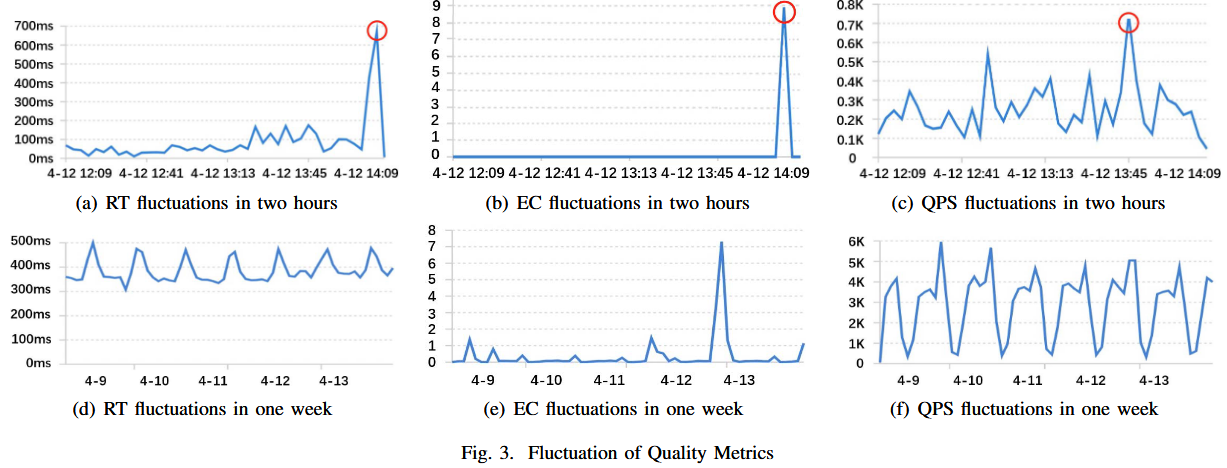
有利于判断有价值的trace。作者拿了华为的一个真实场景进行分析,如Fig.
3所示,[a,b]时间段 Node A 的 MySQL服务进行全表查询,导致 Node A
的CPU被打满,到达 Node A
的请求变得异常。SREs通常先检查系统状态,发现CPU升高,然后分析经过 Node A
的traces。然而,如果只根据密度进行trace采样,那么[a,b]的traces将被采集的很少,因为还没有发生异常。如果结合系统状态进行采样,那么[a,b]的traces将给予更高的采样权重([a,b]存在CPU攀升)。
[1] Ailing Zeng, Muxi Chen, Lei Zhang, and
Qiang Xu. 2023. Are transformers effective for time series forecasting?.
In Proceedings of the AAAI conference on artificial intelligence, Vol.
37. 11121–11128.
[2] Yu Gan. An Open-Source Benchmark
Suite for Microservices and Their Hardware-Software Implications for
Cloud & Edge Systems. ASPLOS, 2019.
https://github.com/delimitrou/DeathStarBench