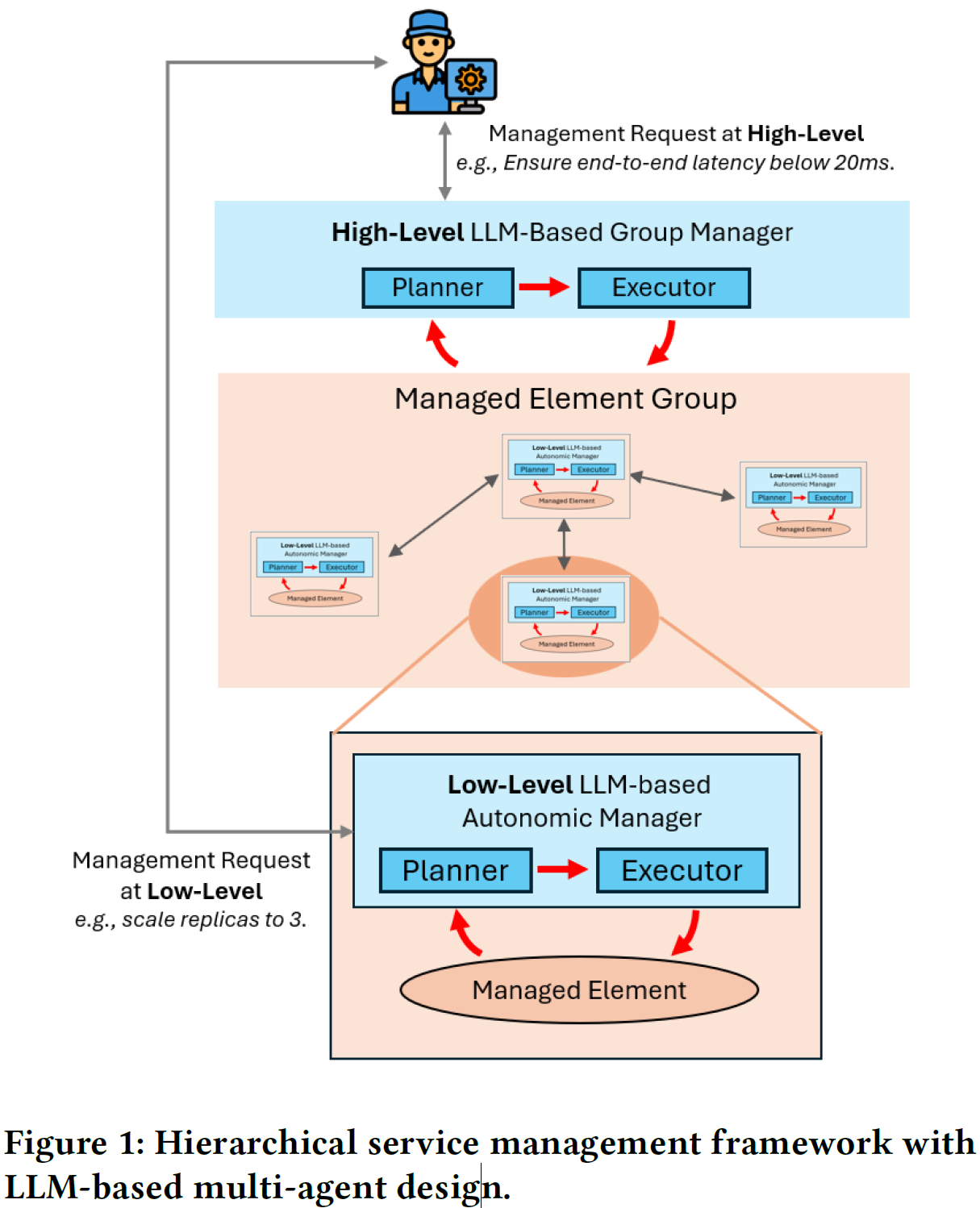
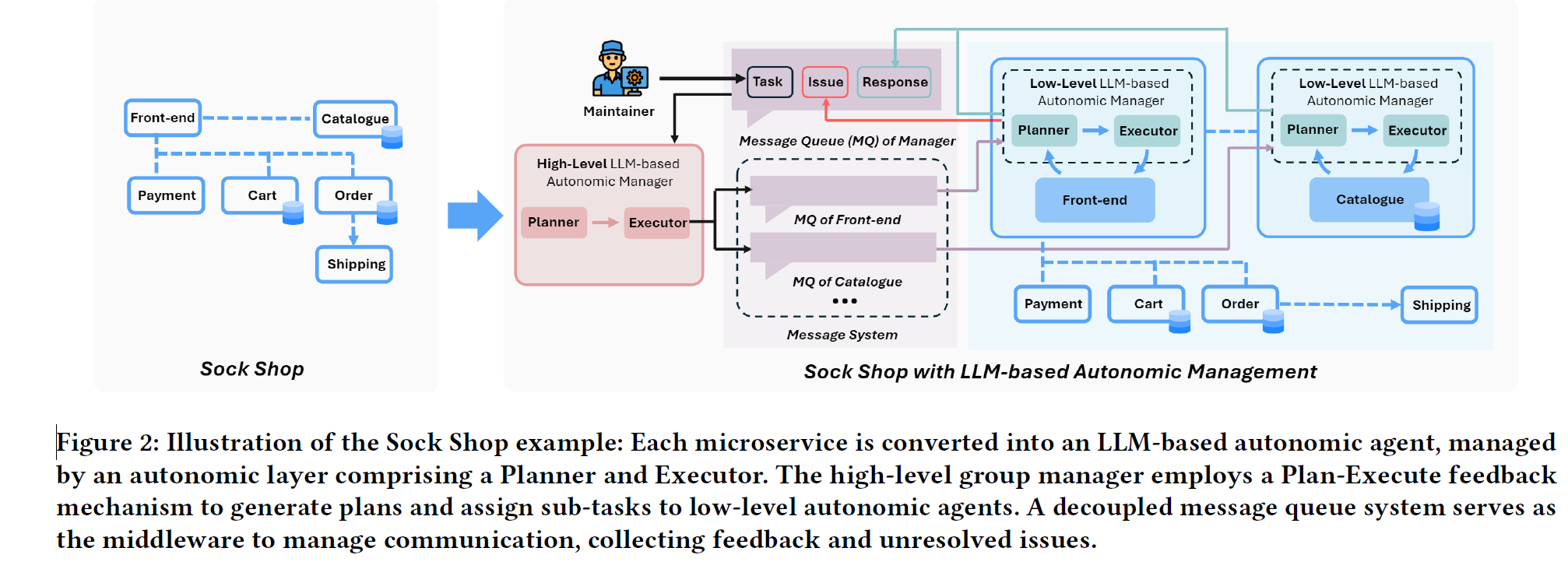
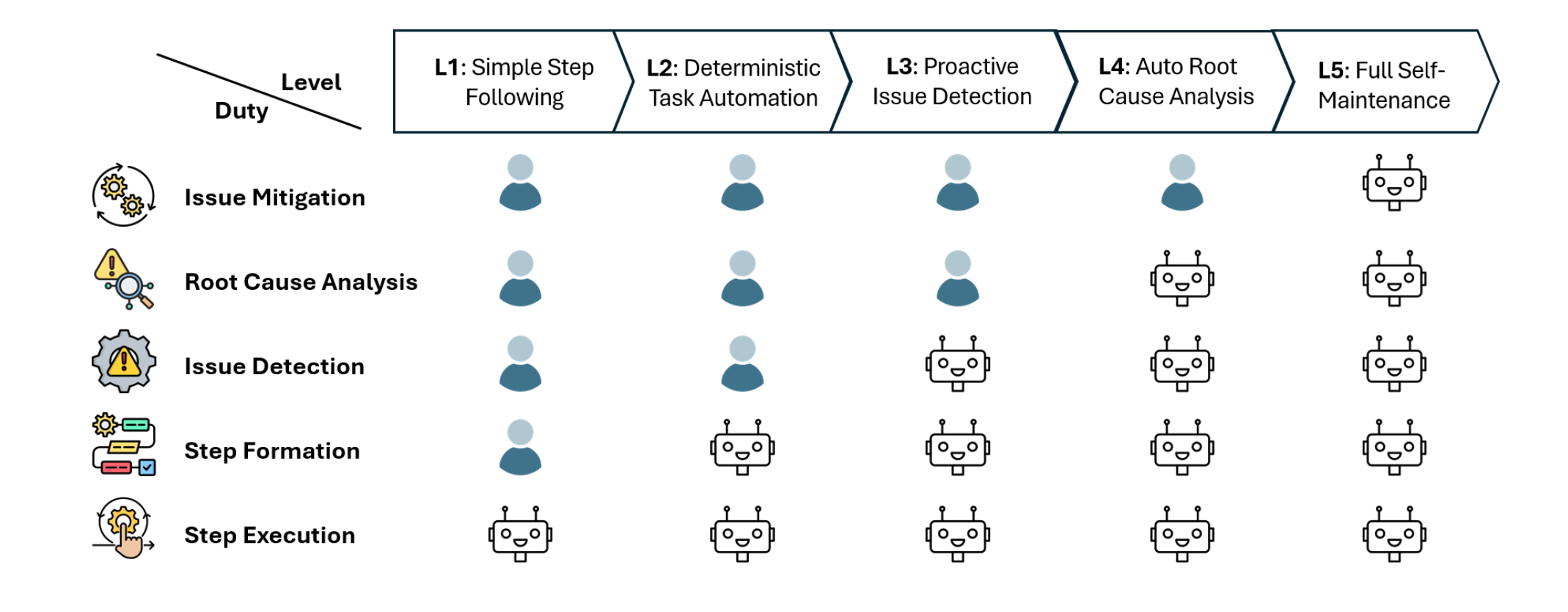
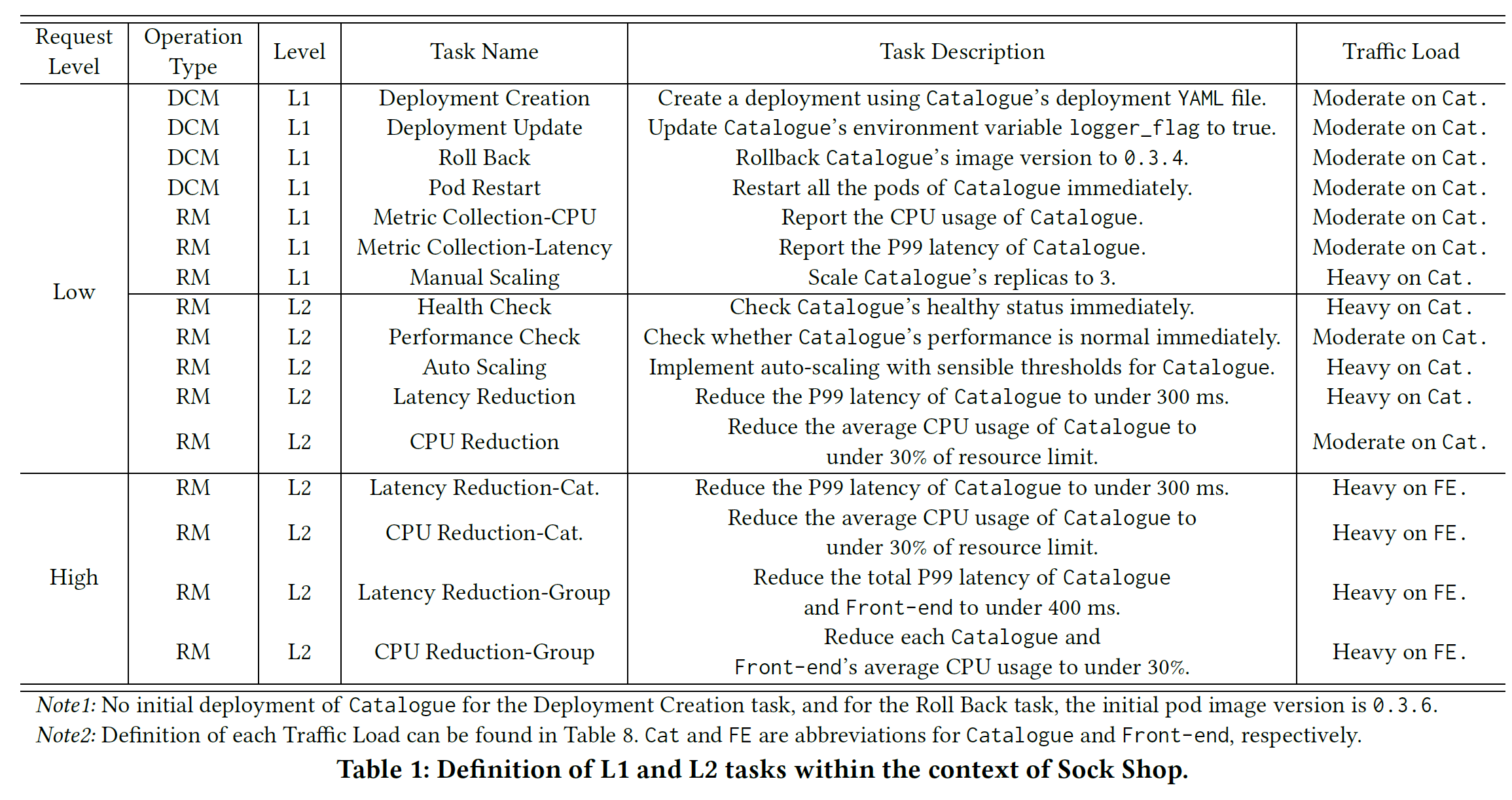
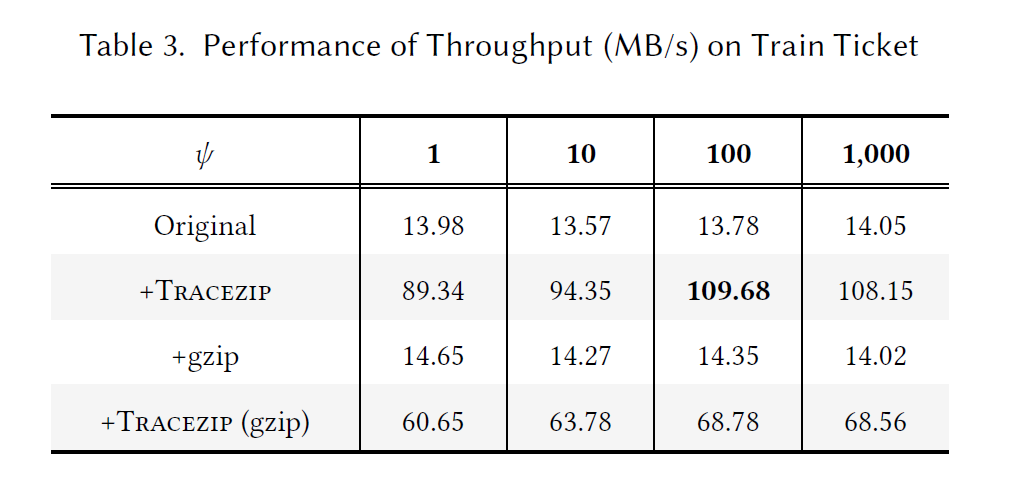
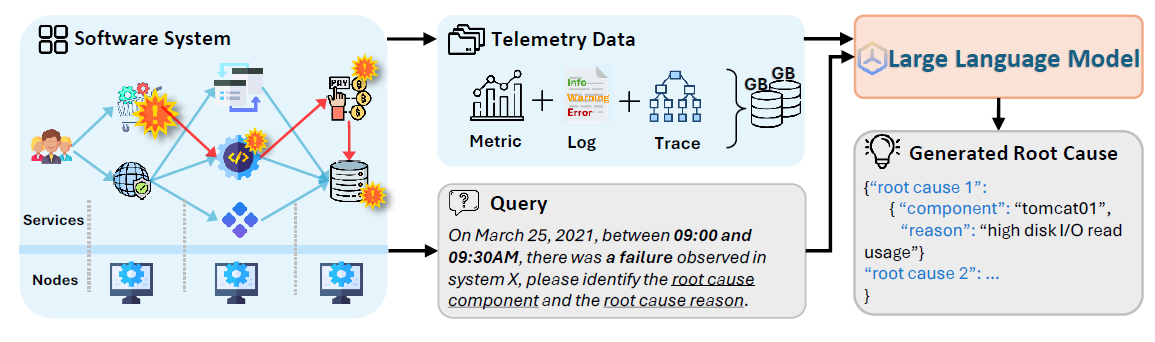
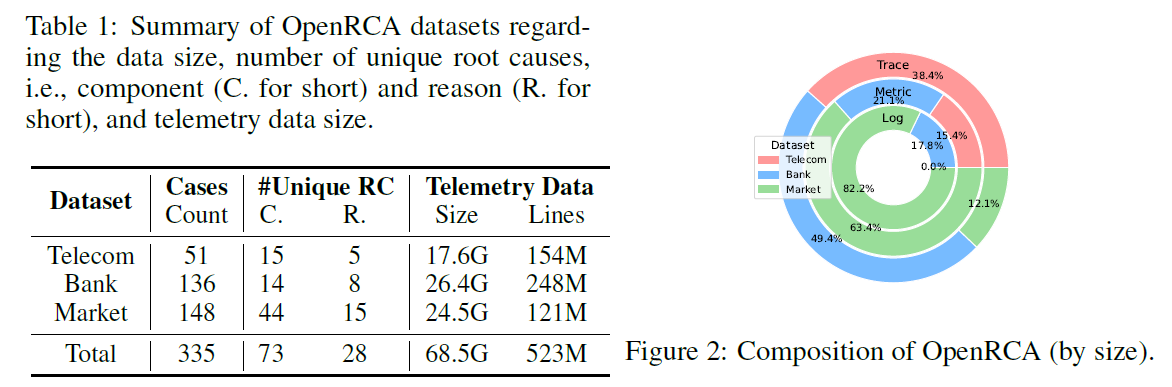
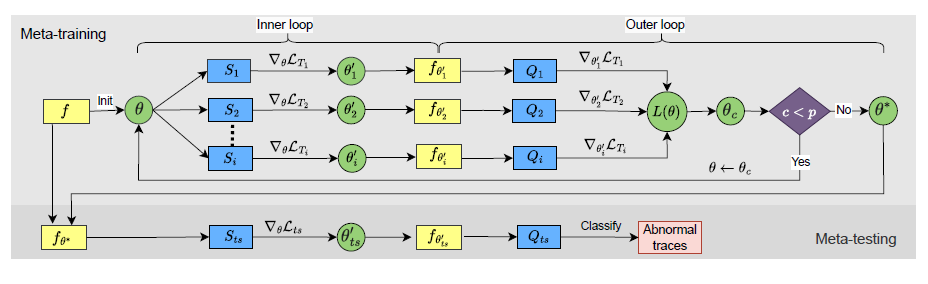
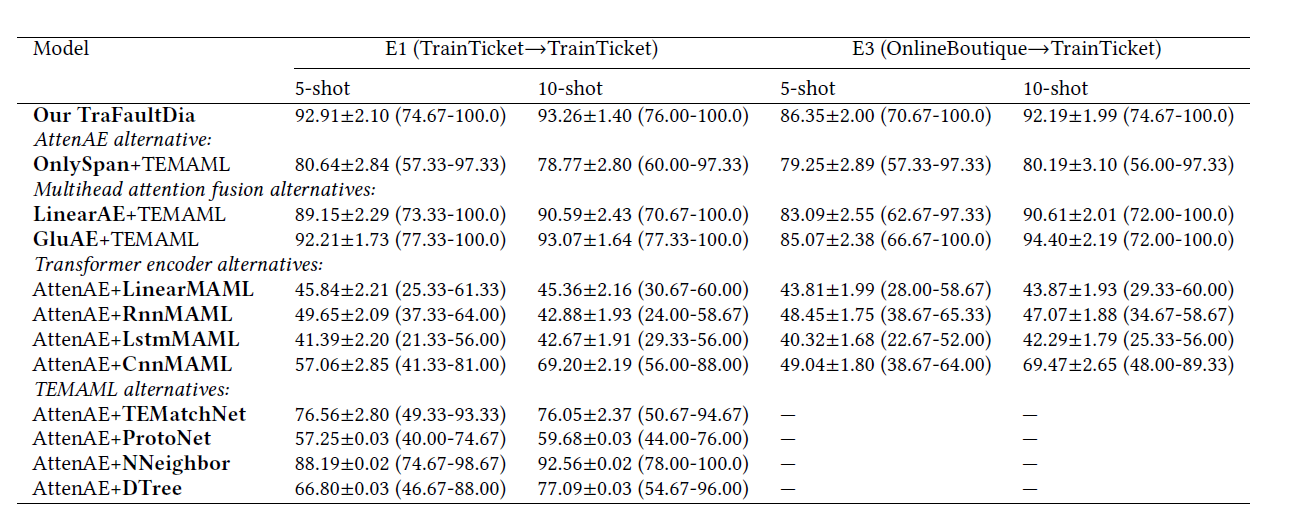
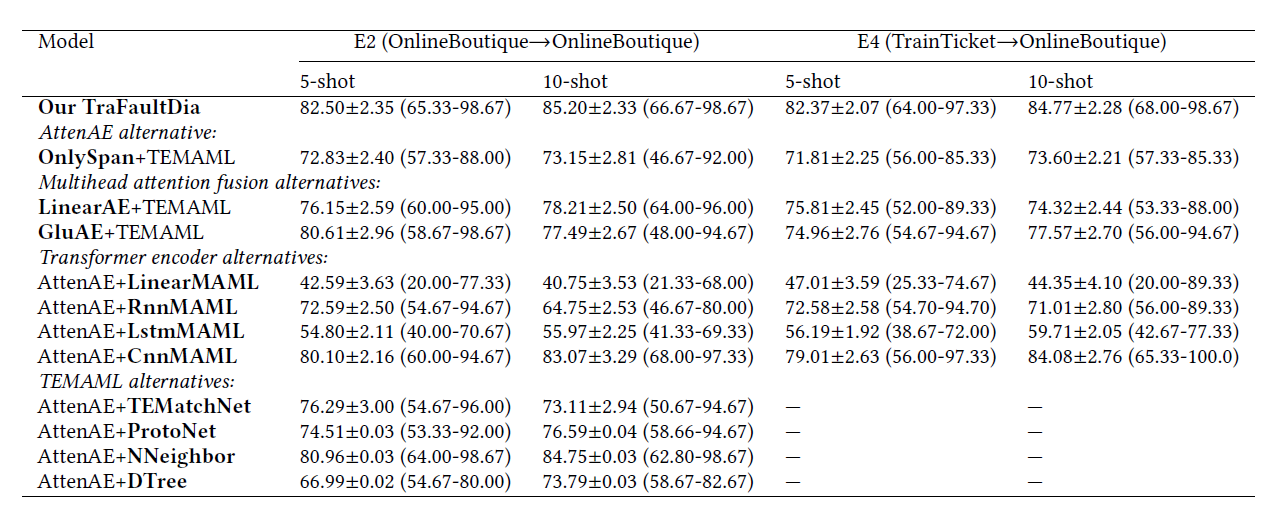
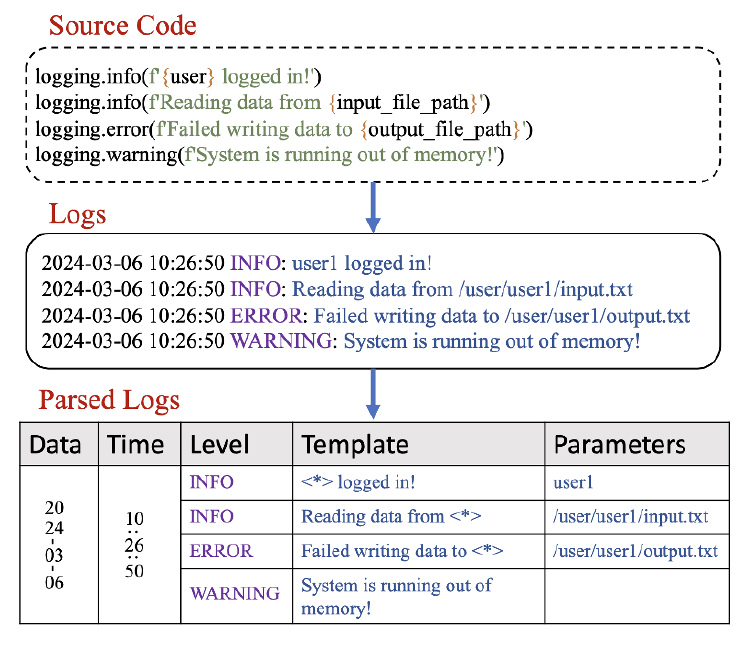
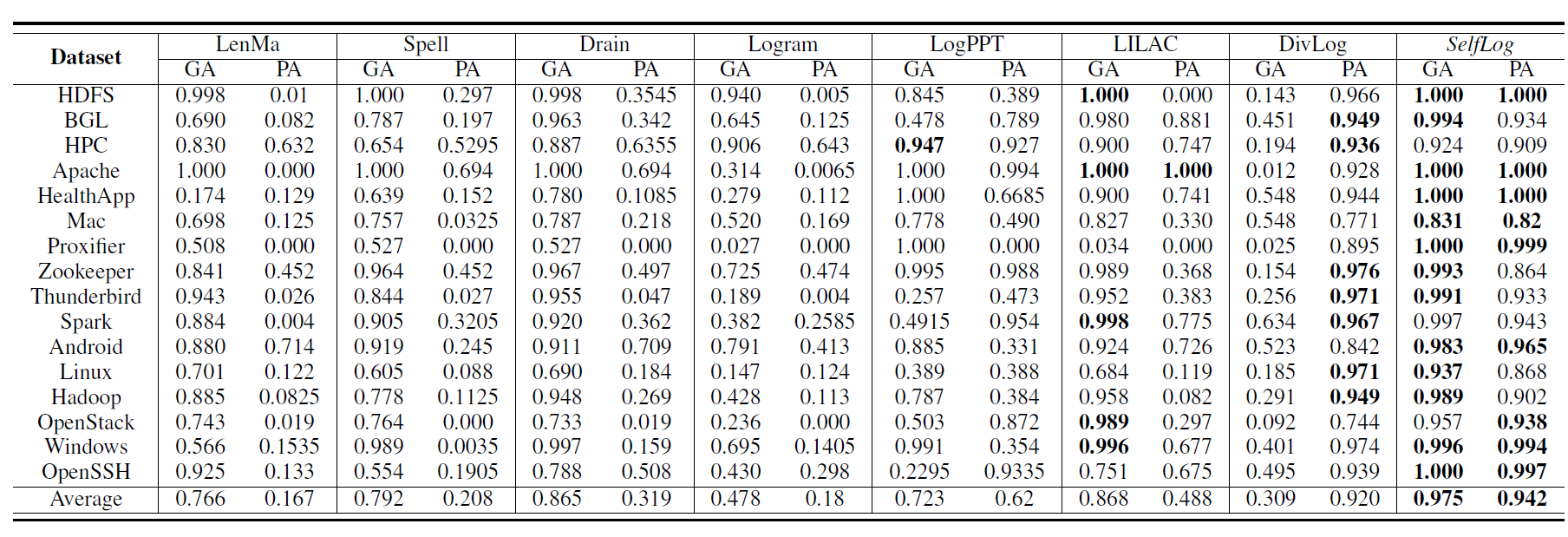
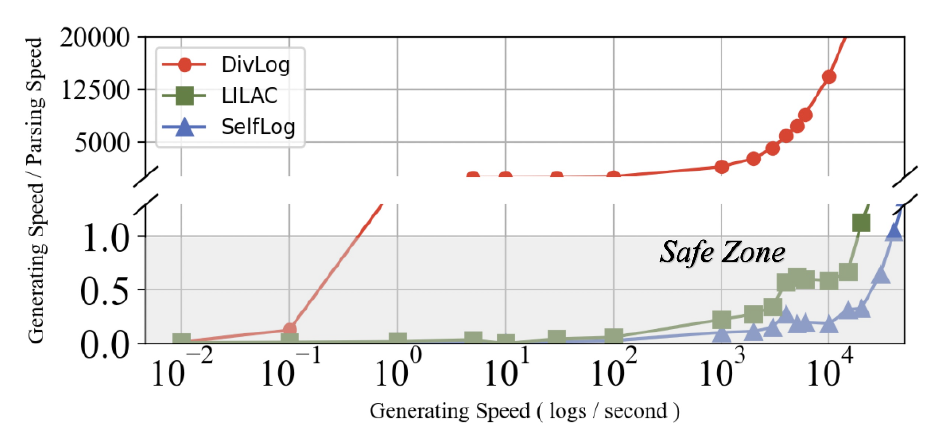
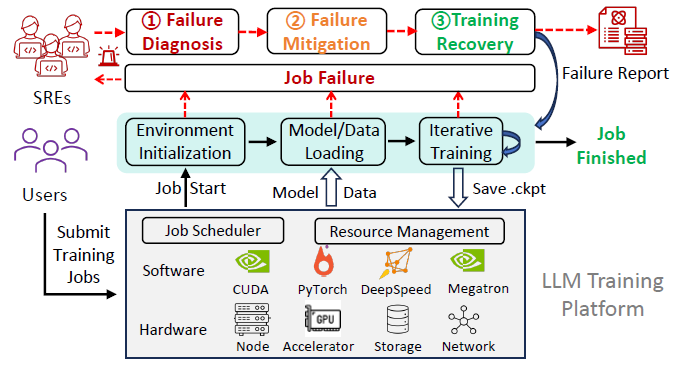
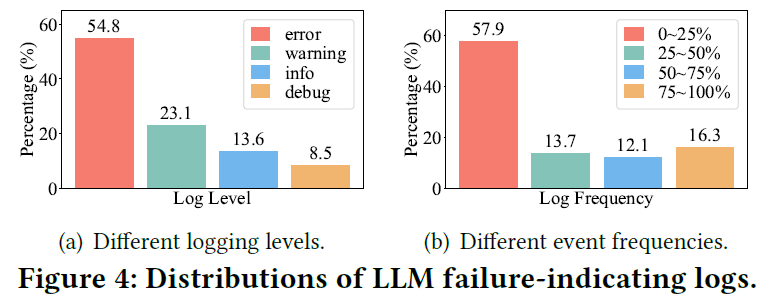
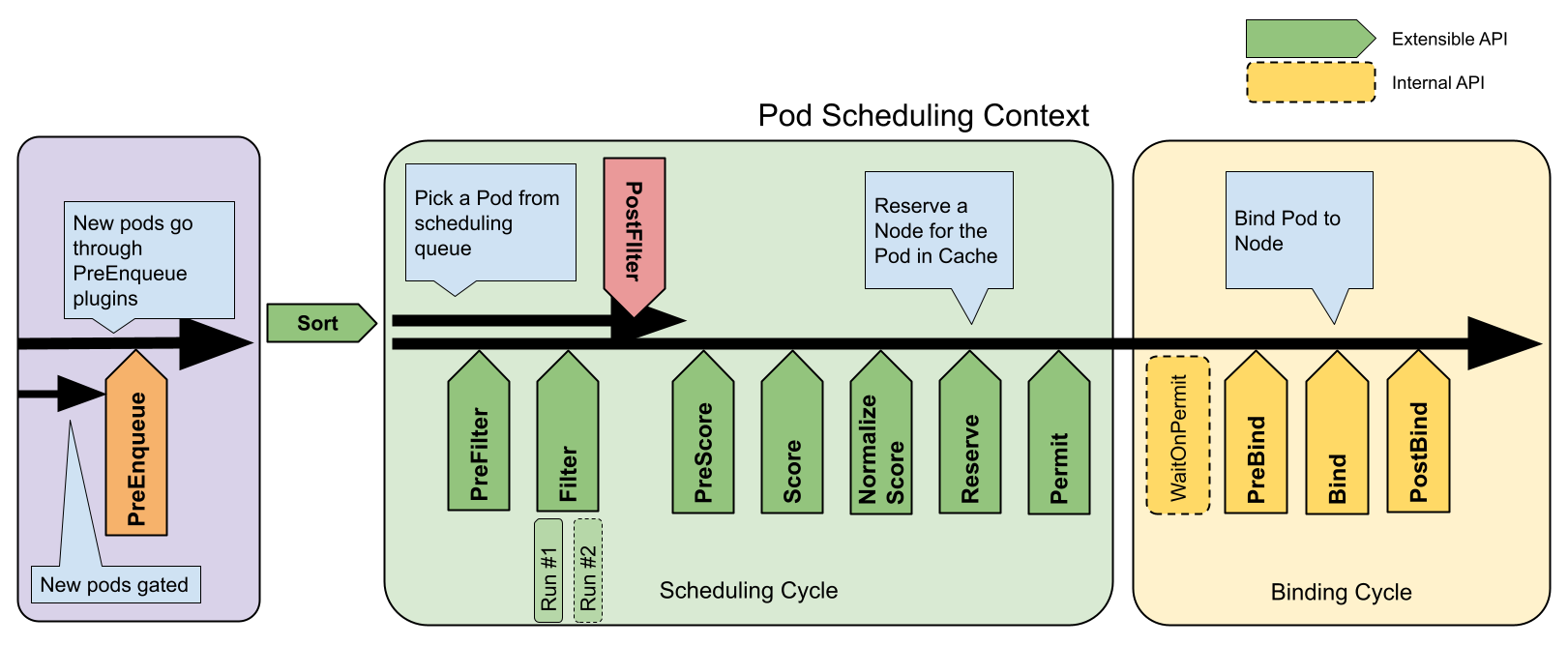
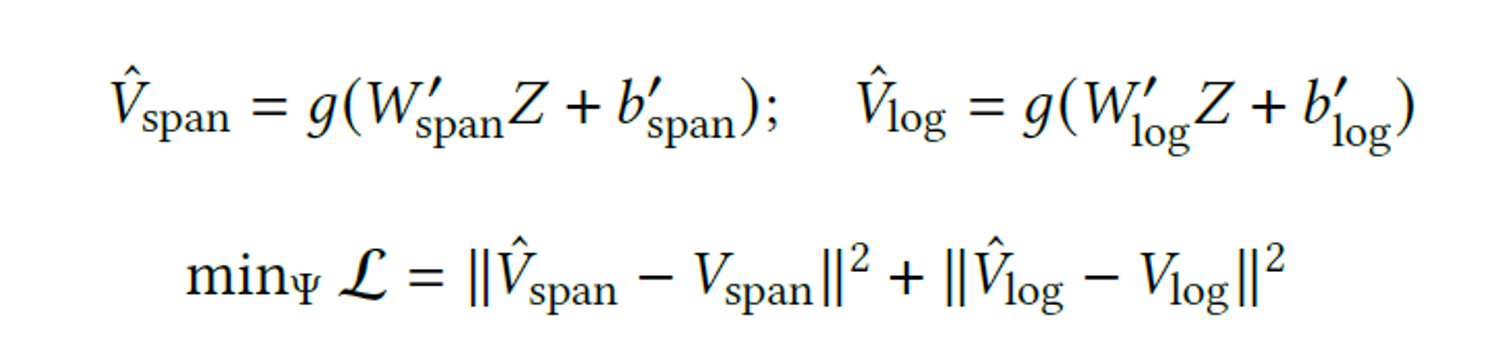题目:ElasticRec: A Microservice-based Model Serving Architecture
Enabling Elastic Resource Scaling for Recommendation Models
来源:ISCA 2024
作者:韩国科学技术院
摘要
推荐系统(RecSys)广泛应用在许多线上服务中,为增加RecSys的推理时的吞吐量,数据中心通常对RecSys进行模型级别(model-wise)的资源管理。然而,RecSys中不同模块有着异构的资源需求,比如:
RecSys中MLP模块 对于计算资源的需求高RecSys中Embedding Table模块对于内存资源的需求高
如果将RecSys模型看作一个整体进行服务部署、资源分配等操作,势必会造成大量的资源浪费;但对RecSys模型中的每一层进行资源管理又是非常具有挑战性的(这里类似于单体应用和微服务应用的关系)。因此,作者提出了ElasticRec,一种基于微服务架构的推荐系统细粒度资源分配方法,目标是减少部署时的内存消耗,提升RecSys的吞吐量。
背景
文章背景主要介绍了深度推荐模型的结构,以及深度推荐模型如何集成到Kubernetes集群中,为用户提供线上推理服务。
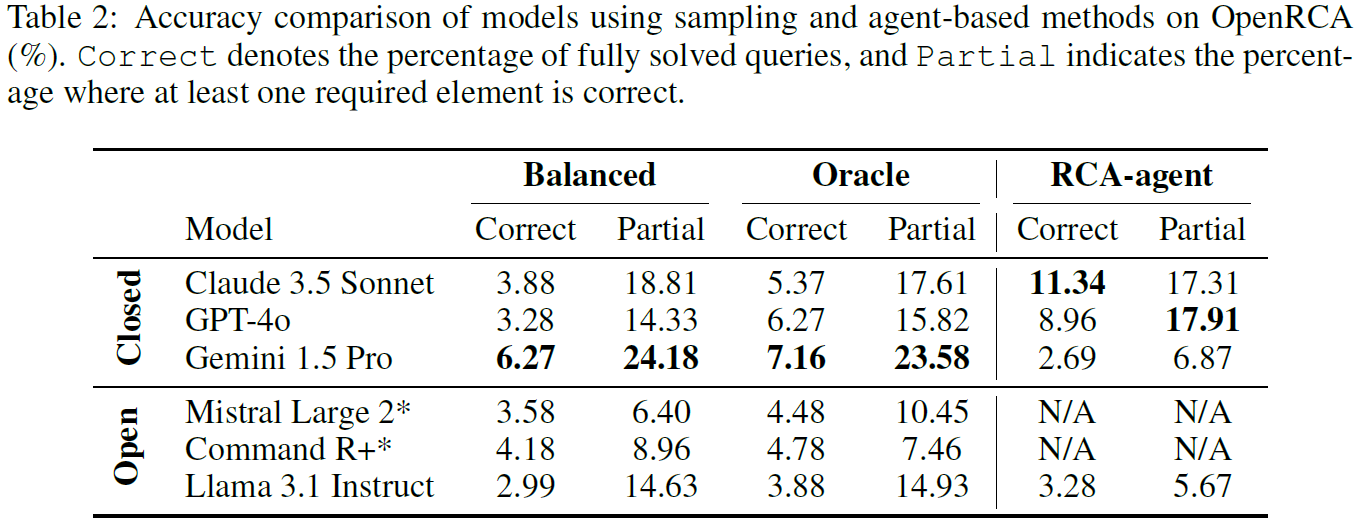
深度推荐模型(DLRM)
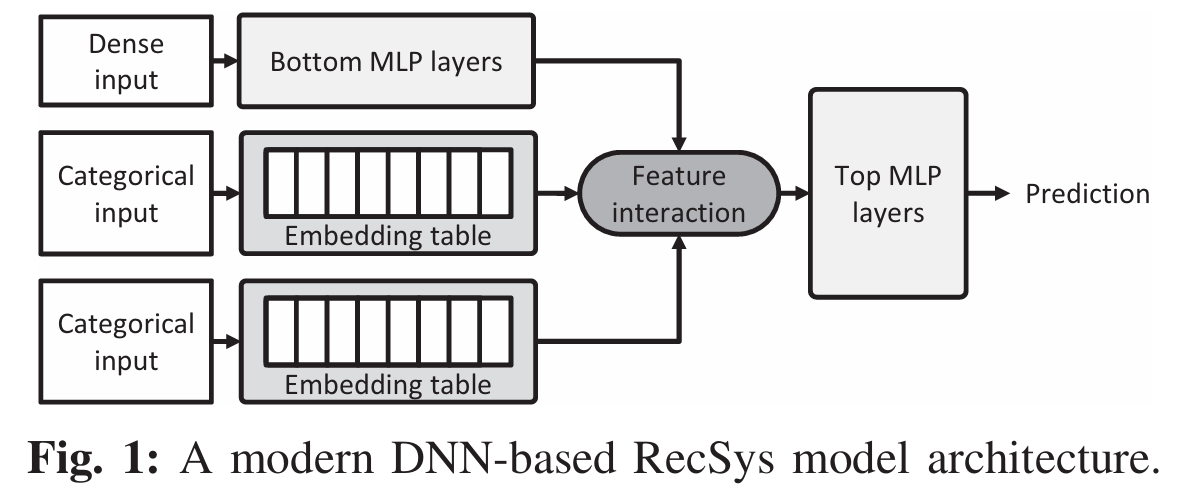
如图所示,深度推荐模型(DLRM)包含3个主要组件:
Bottom MLP
- 输入:dense input(比如 用户年龄)
- 输出:dense output(高维特征)
- 类型:计算敏感型
Embedding Table
- 输入:多个 sparse input(比如 商品ID)
- 输出:dense output(高维特征)
- 类型:内存敏感型
- 作用:根据稀疏输入得到
Embedding Table中的高维特征。一般来说,一次查询中所有的sparse
input得到的dense
output会执行pool操作进行池化,得到单个dense output
Top MLP
- 输入:
Bottom MLP的输出 拼接
Embedding Table的输出
- 输出:给商品打分
在生产环境中,由于商品(item)的种类非常多,比如Amazon有数亿的商品种类。Embedding Table为每个商品种类都维护了一个特征,导致Embedding Table的大小可以达到几十GB,相比于Bottom MLP,有几点需要关注:
Embedding Table对于计算不敏感,即pool操作并不需要太多计算资源;相反,对于内存带宽限制极为敏感,特别是有非常多的dense
output需要pool时- 在
DLRM中,Embedding Table通常有多个,对内存的压力是极大的
模型服务架构(Model
Serving Architectures)
模型容器化
这篇文章关注的是DLRM的推理。在线上应用中,DLRM被打包成镜像,镜像中包含了模型参数以及常用的机器学习库,以容器的方式运行在Kubernetes集群中,如Fig.
2(a)所示。
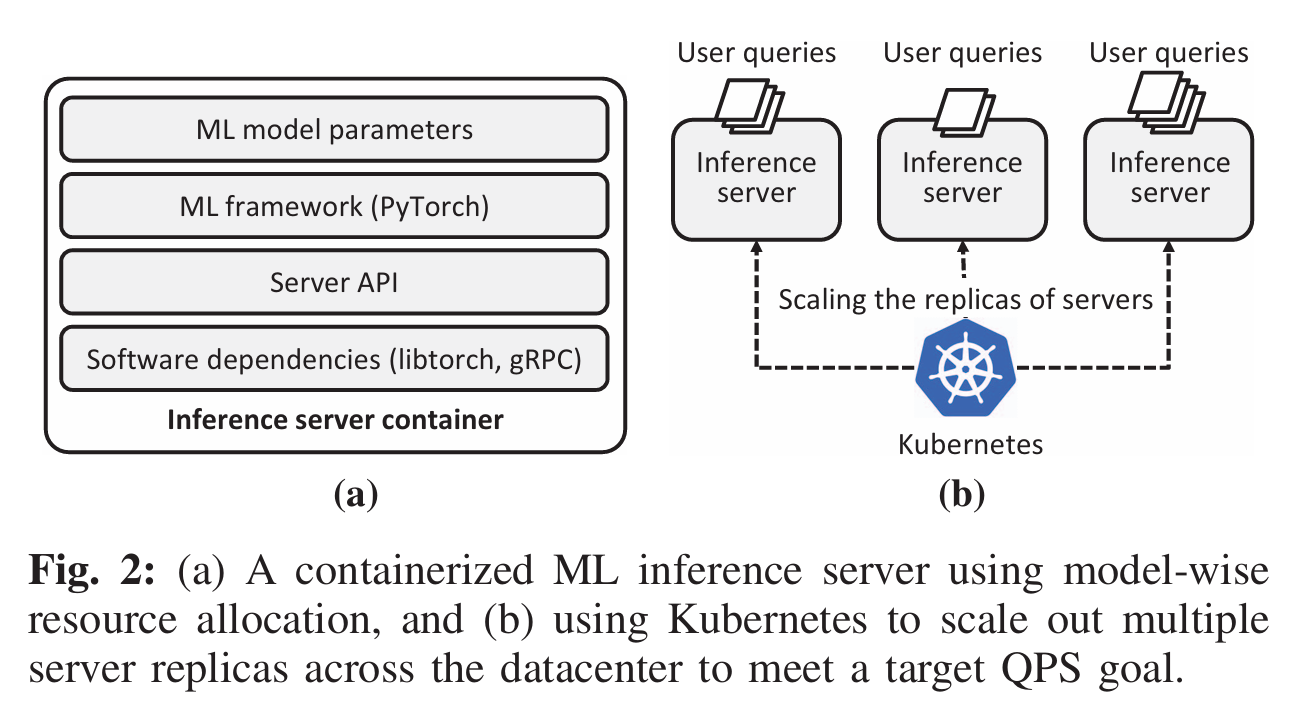
模型的自动伸缩
Kubernetes是一个容器编排工具,它能管理容器的生命周期,对容器进行自动化调度、资源分配。
吞吐量是一个衡量在线服务性能的指标,单位是QPS(query
per second),吞吐量越高,代表在线服务单位时间内处理请求的数量
对于DLRM而言,处理单个请求的时间基本可以看作变化很小的,那么为提高吞吐量,可以采用Kubernetes的水平pod伸缩(Horizontal
Pod Autoscaling,HPA)机制对DLRM进行副本复制,如Fig. 2 (b)
所示,增加DLRM的副本数可以提高系统的并行处理能力,从而增大吞吐量
然而,HPA 是一种 model-wise
的分配方案,它将整个DLRM模型进行复制,包括内存占用非常大的Embedding Table模块,但实际上Embedding Table并不涉及复杂的计算,所以一般不是(不是绝对)吞吐量的瓶颈所在。无脑进行HPA势必会造成大量内存浪费。
模型的硬件约束
因为 大型 DLRM 的 Embedding Table
通常有几十GB,将 Embedding Table
全部放在高内存带宽的GPU中通常不太可行,所以会退而求其次的使用如下两种方式:①
CPU-only ② CPU-GPU。
- CPU-only:
Bottom MLP 和
Embedding Table 均运行在CPU
- CPU-GPU:
Bottom MLP 运行在GPU,
Embedding Table 均运行在CPU
可以看到, Embedding Table
都运行在CPU关联的内存上,如果能优化这一部分的内存使用,就可以提升DLRM的最大副本数量,从而提高系统的吞吐量。
动机
文章的动机从两点出发,阐述为什么现有的资源分配方案会导致次优性能(sub-optimal
performance):
RecSys的不同模块具有异构资源需求Embedding Table不同部分的访问频率相差极大
异构资源需求
Fig. 3 (a)
展示了三个推荐模型(RM1,RM2,RM3)的不同模块Bottom MLP 和
Embedding Table 在 ①计算复杂度(FLOPS)和 ②内存大小
上的差别。可以看出:Bottom MLP在计算复杂度上远高于
Embedding Table,但是内存占用远远小于
Embedding Table
Fig.3 (b)
展示了三个推荐模型的不同模块在两种硬件约束下的延时占比。原文虽然没有讨论,但可以推测,在CPU-only架构下,推理的延时开销主要集中在Bottom MLP的计算;在CPU-GPU架构下,延时的开销在于将 Embedding Table
的数据从CPU传输到GPU

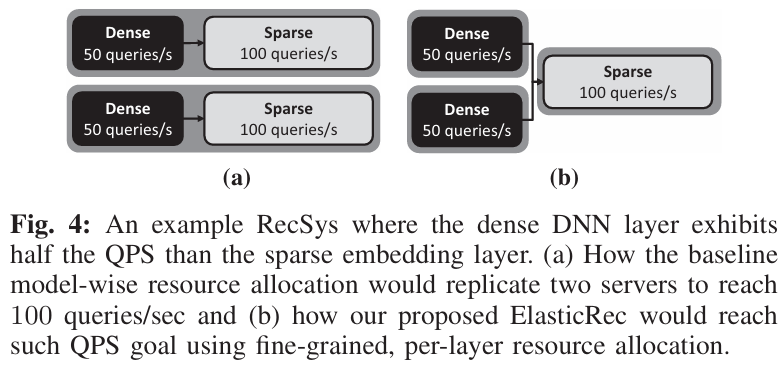
此外,文章还讨论了吞吐量的瓶颈问题,Fig.
4展示了作者的想法,实际上Bottom MLP
计算开销大,内存占用小,适合扩充副本来提升吞吐量;而
Embedding Table
本身吞吐量就很大,但是内存占用大,所以对于副本扩充应该谨慎。
当然,作者还通过实验,验证了不同硬件约束下不同模块的吞吐量存在差异,来支撑上述想法:

综上所述,文章说明RecSys中不同模块的异构资源需求,以及吞吐量的差异。为后续对不同模块分别进行切分提供了实验依据
Embedding Table
的倾斜访问模式
这一个实证分析较为简单,主要验证Embedding Table不同索引的访问频率的差异,如Fig.
6所示,在三个数据集中,大部分的访问集中在少数的索引(热点嵌入,hot
embeddings)
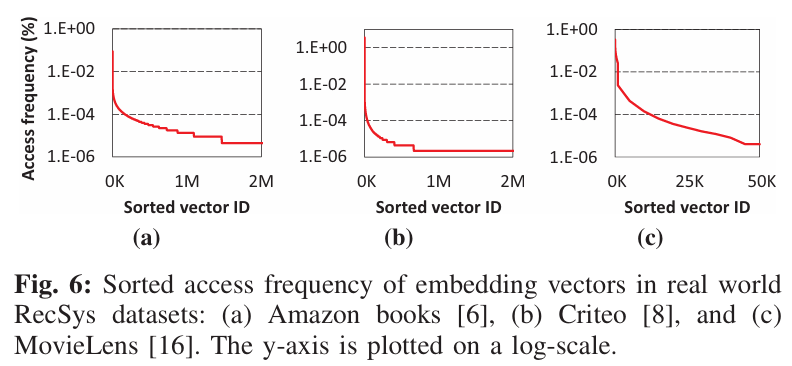
换句话说,将资源选择性地分配给 hot
embeddings,可以在提升吞吐量的同时,达到节省资源的目的
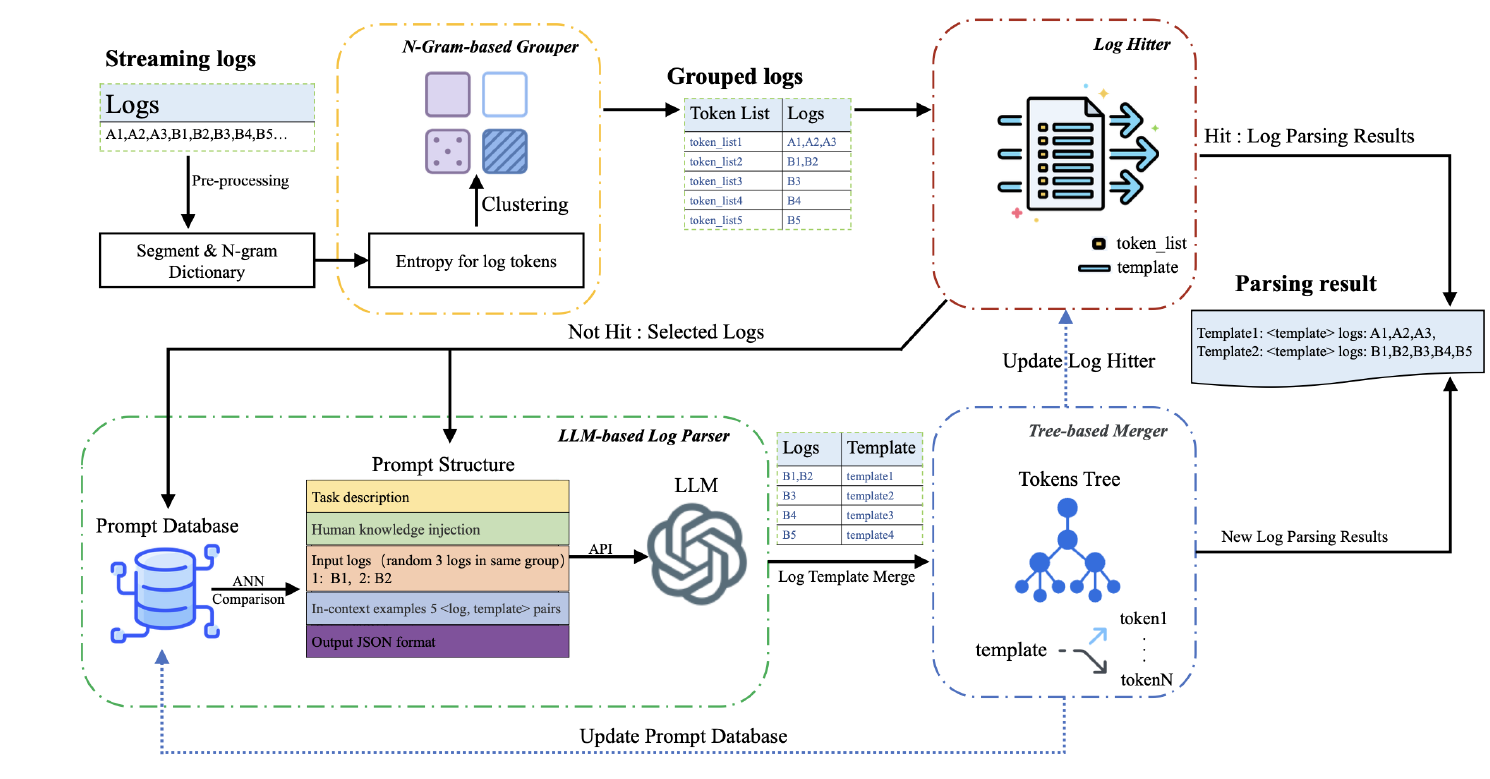
方法设计
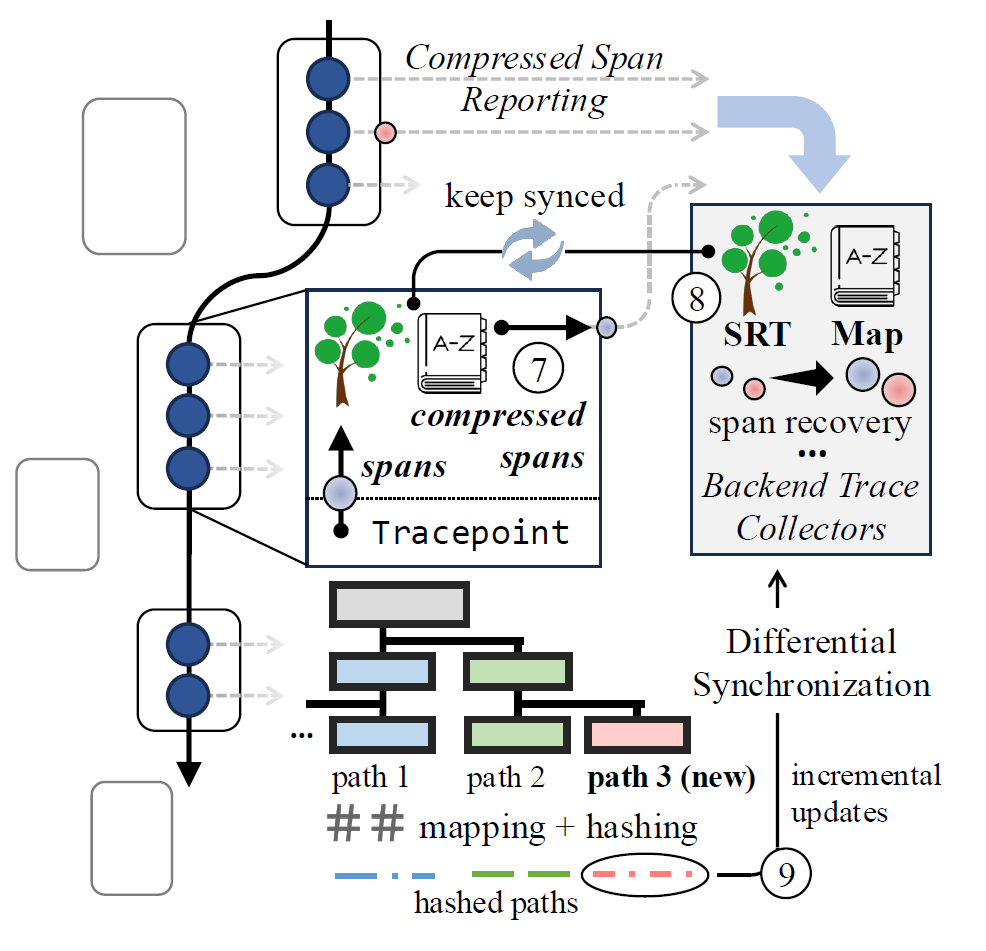
Fig. 7展示了ElasticRec的系统架构,整体思路分为三个模块:
- 部署开销估计
- 基于动态规划(DP)的
Embedding Table划分
- 推理时重索引
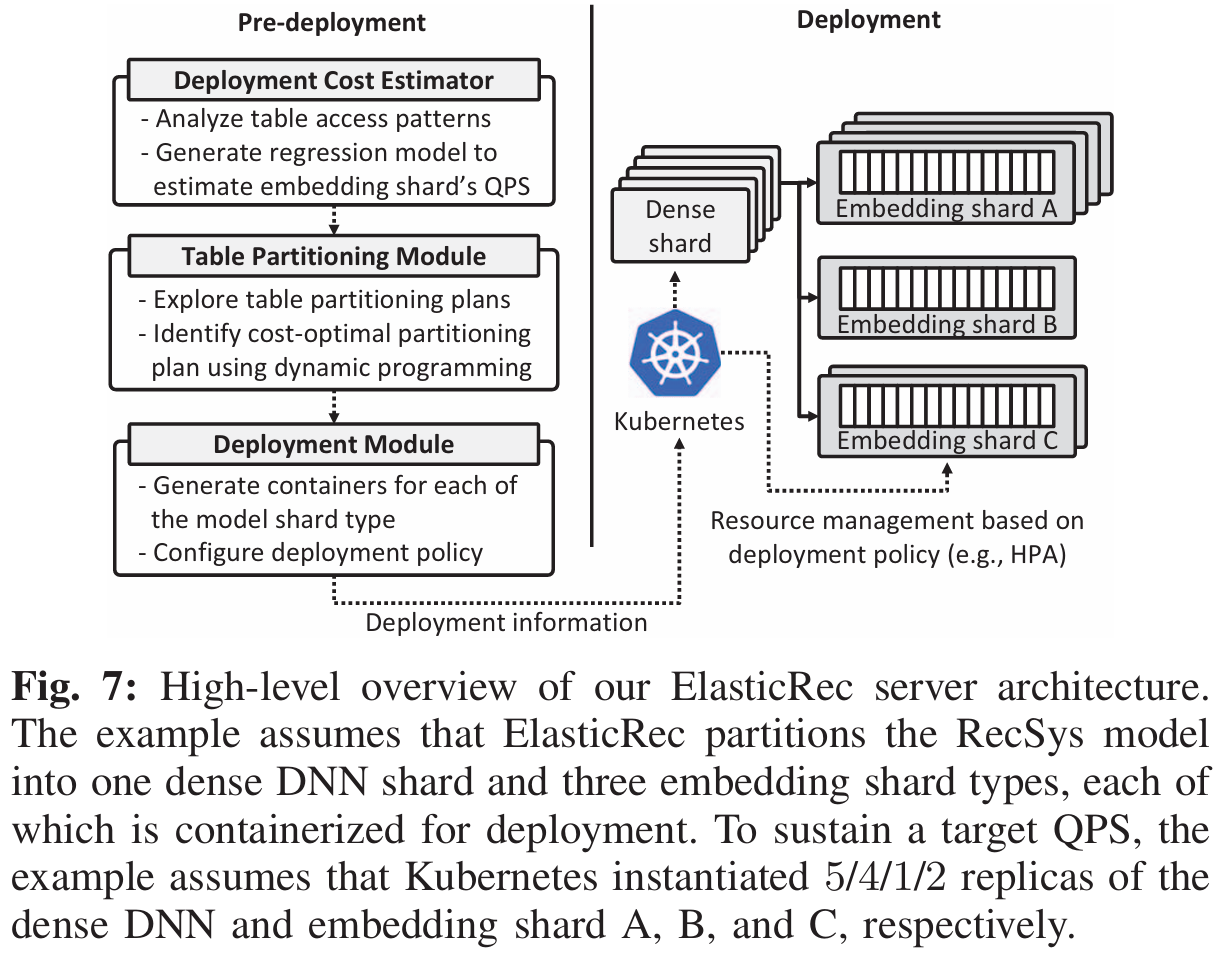
部署开销估计
前置处理:将Embedding Table的index按照访问频率从大到小排序,hot
embeddings集中在最左侧
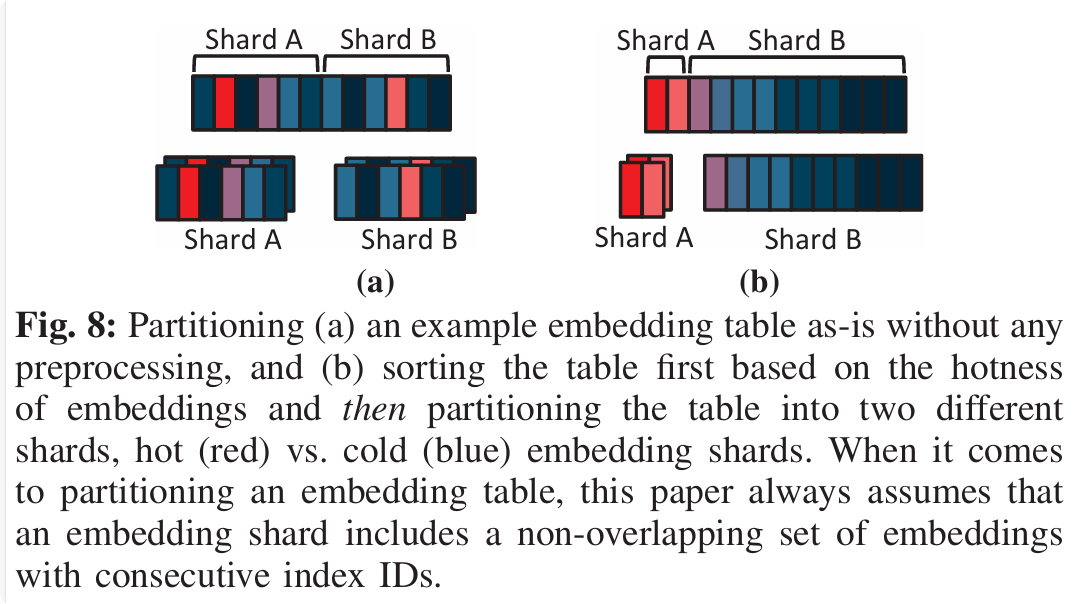
根据动机中提到的“将资源选择性地分配给 hot
embeddings,可以在提升吞吐量的同时,达到节省资源的目的”,文章将Embedding Table切分为shards,每个shard包含了Embedding Table的一部分index。那么如何切分Embedding Table,以及如何评估切分策略的优劣呢?
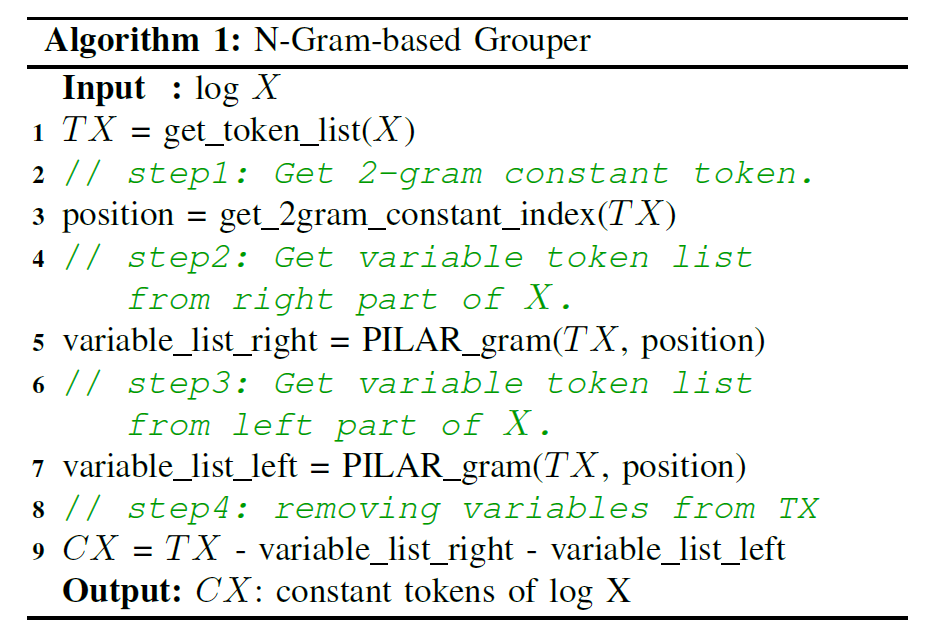
文章首先定义了如何评估切分策略的优劣,切分策略的优劣由固定吞吐量的前提下,所有shard的内存开销决定。用最少的内存达到目标吞吐量,评估算法如下:

算法入口为COST(k, j),表示范围为[k,j]的shard的内存消耗,这个内存消耗由两部分组成:
REPLICAS(k,j):
计算特定吞吐量下,shard应该被分配的副本数量
- 计算shard被访问的概率
probability和被访问的向量数ns,probability = CDF(j)- CDF(k),ns = probability × nt
- 估计单个shard的副本在给定的访问向量数
ns下能达到的QPS,estimated QPS = QPS(ns),这里的QPS()是一个回归模型,可以线下测试得到
- 估计达到目标吞吐量
target_traffic需要的副本数,num_replicas = target_traffic/estimated_QPS
CAPACITY(k,j):对于shard的每一个副本,计算存储embedding的内存开销
- 直接计算shard的副本大小:
(j − k +1)×(size_of_a_single_embedding_vector)
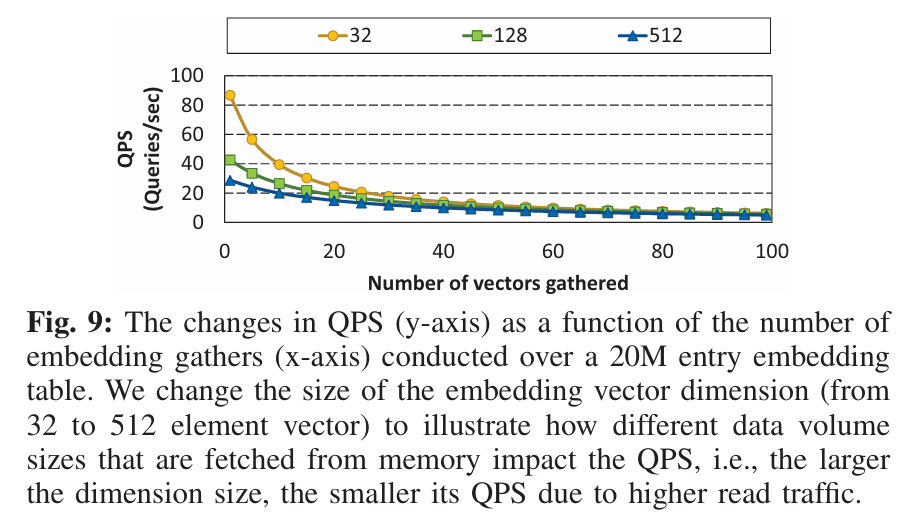
这里需要特别注意回归模型QPS(),输入的参数除了需要访问的向量数ns外,还需要考虑向量本身的大小,如下图所示,QPS既与向量数有关,也与向量本身维度相关
基于DP的Embedding Table分区算法
在上一节中,当给定一个shard划分策略,我们可以评估每个shard在目标QPS下的内存开销,进而可以尝试找到给定QPS下最小内存开销的分区策略
这里文章有一个前提,即无论怎么划分,所有shard的目标QPS都是一样的,这样可以保证不存在多余的资源浪费
这个分区问题有两个操作:① 分多少shard
②每个shard的范围。假设我们用\(Mem[num_{shards}][x]\)表示Embedding Table在\([0:x]\)范围下,分区数量为\(num_{shards}\)的最小内存开销。那么这个问题具有两个明显的特性:最优子结构和重叠子问题
最优子结构:\(Mem[num_{shards}][x]\)可以由子问题的最优解构造而来,假设最后一个shard的大小为\(m\),那么可以简化表示为\(Mem[num_{shards}][x] =
min(Mem[num_{shards}-1][x-m] + COST(m))\),比如下图中,\(Mem[3][5]=min(Mem[2][5-m]+COST(m))=Mem[2][3]+COST(4,5)=4\)
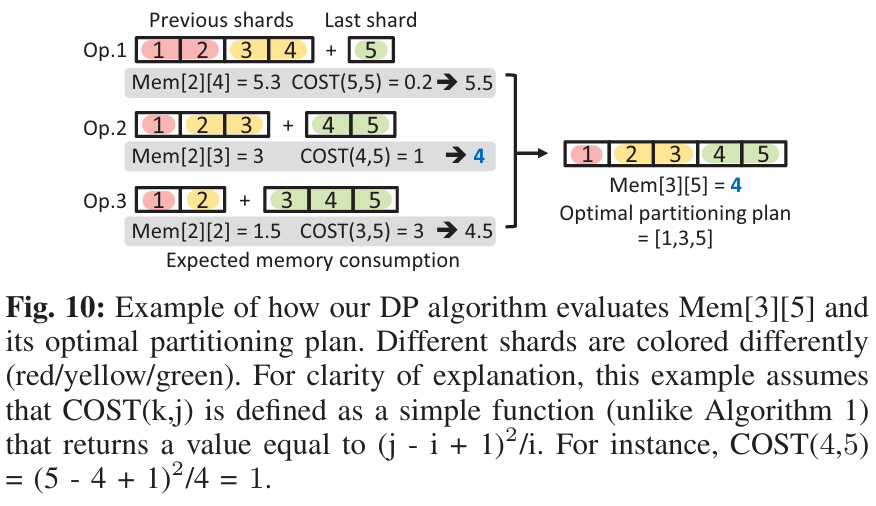
重叠子问题:求解过程中会反复遇到相同的子问题,需要将结果存储到表中,避免重复计算
因此,自然而然可以想到用动态规划(DP)求解,文章给出的算法如下:

最后根据最小内存开销回溯DP表可以得到分区策略
推理时重索引
这个部分的重点在于分区后,如何根据原始Embedding Table的index
ID找到对应的shard中的某个embedding,以及确认index分别属于哪个input(为提高吞吐量,一个query包含了多个input)。

文章提出了两种索引:
indices:存储一次query要从Embedding Table中查找的具体ID。offset:指示每个input对应的的indices中的起始位置。
对于Fig.
11(a)未分区前,一个query(indices)包含了两个input,分别为红色的[1,
7],灰色的[3,4,8],offset表示第一个input要从indices第0个元素算起,第二个input从indices第1个元素算起,即input1为[1,7],input2为[3,4,8]
对于Fig.
11(b)分区后,首先计算中间的indices,具体为根据indices中的index计算应该被分到哪个分区(减去之前分区的大小),可以很容易把indices划分为shard
A 的[1,3,4]和shard B
的[7,8],同时把offset进行划分(基于indices)
对于Fig.
11(b)分区后,由于各shard索引重置了,所以需要在中间的indices和offset的基础上,进行重索引,具体为减去之前分区的大小,比如Fig.
11(b) 中 shard B的[7,8]减去shard
A的大小后,变成[1,2]。这样便可以直接从各shard中查找embedding了
最终部署
因为Kubernetes的 horizontal pod autoscaling
提供了弹性伸缩时参考指标的接口,对于:
Embedding Table的shard,文章直接将每个shard可以承受的最大吞吐量作为参考指标,到达最大吞吐量则扩容Bottom MLP,则采用SLA的65%作为扩容的阈值
(这里不是很明白为什么要采用不同的阈值指标,为什么不都用吞吐量?)
实验部分
文章分别验证了 ElasticRec 在 CPU-only
以及 CPU-GPU 环境下的性能表现:
- CPU-only:本地集群(1 master + 11 worknode)
- CPU-GPU:云集群(20 CPU-GPU nodes,GPU为 NVIDIA
Tesla T4,节点间有31Gbps的带宽)
DLRM模型的开发是基于facebook的dlrm1。Kubernetes自动伸缩器采用的custom
metric来自prometheus。SLA设置为400ms。而对于验证的DLRM模型,作者选择了三个先进的推荐模型(RM1,
RM2,
RM3),并在RM1的基础上进行参数改造,设置了很多个microbenchmarks,参数变动和三个RM模型如下:
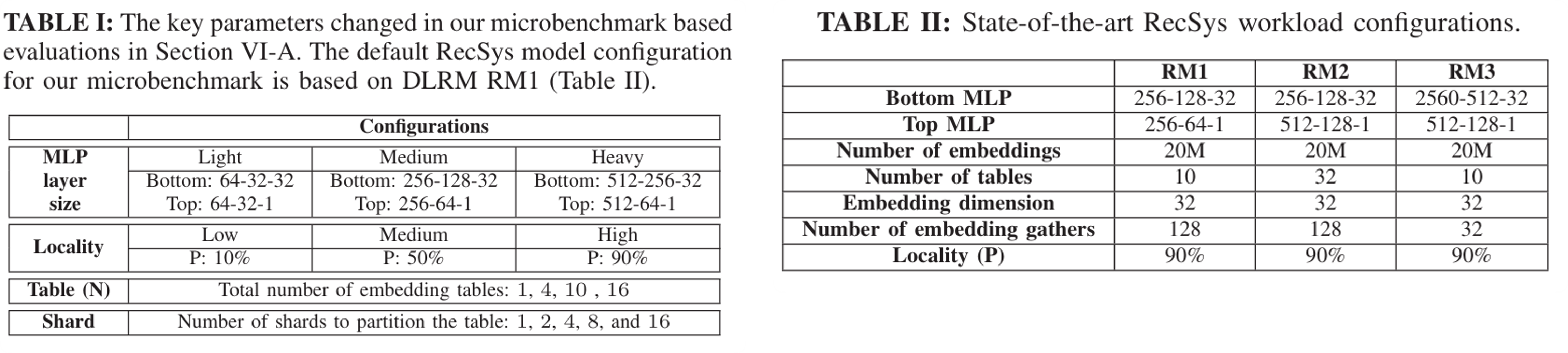
其中 Locality 指标 \(P\)
代表多少请求分布在前10%的热点向量,\(P\)越大,代表请求分布越集中在热点。
Microbenchmarks实验
文章一开始探讨了不同RM配置下的内存消耗:
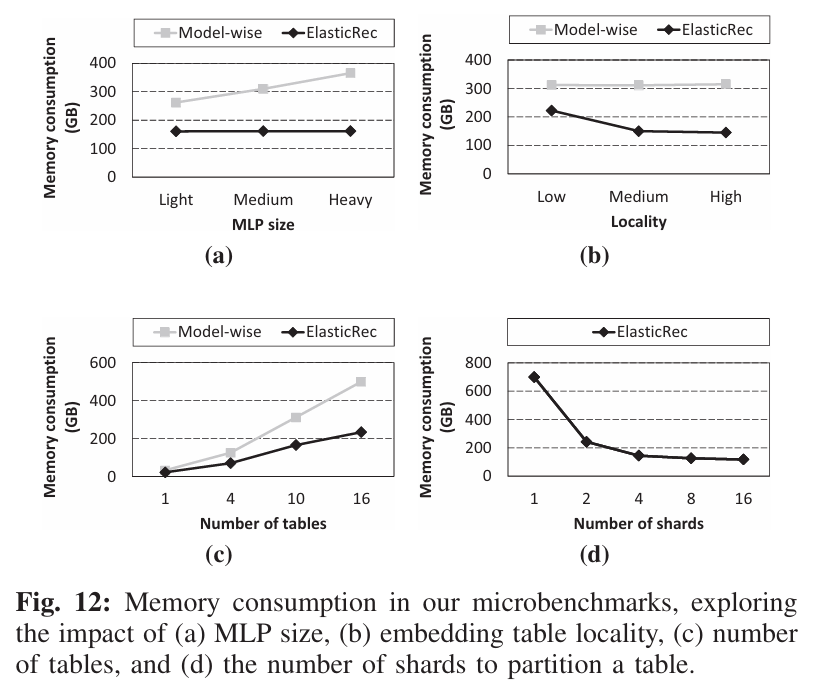
- MLP size:随着MLP
size的扩大,计算复杂度提高,延时会逐渐违背SLA。
Model-wise的方法会扩容整个模型,而ElasticRec只需要扩容内存开销极小的Bottom MLP,所以内存消耗差距很大
- Locality:访问越集中在热点,
ELasticRec效果越好,因为只需要扩容热点那一部分
- Number of
tables:系统中可能不止一个
Embedding Table,比如用户ID表和商品ID表,随着表数量的增多,ELasticRec对每个表都进行分片,降低扩容时的内存开销
- Number of
shards:分片数量并不是越多越好,因为每个shard会有最小内存消耗(程序运行必须的消耗),即算法1中的min_mem_alloc,所以当分片数量大于4后,效果没有那么明显了
不同 RM 在 CPU-only
环境下的性能
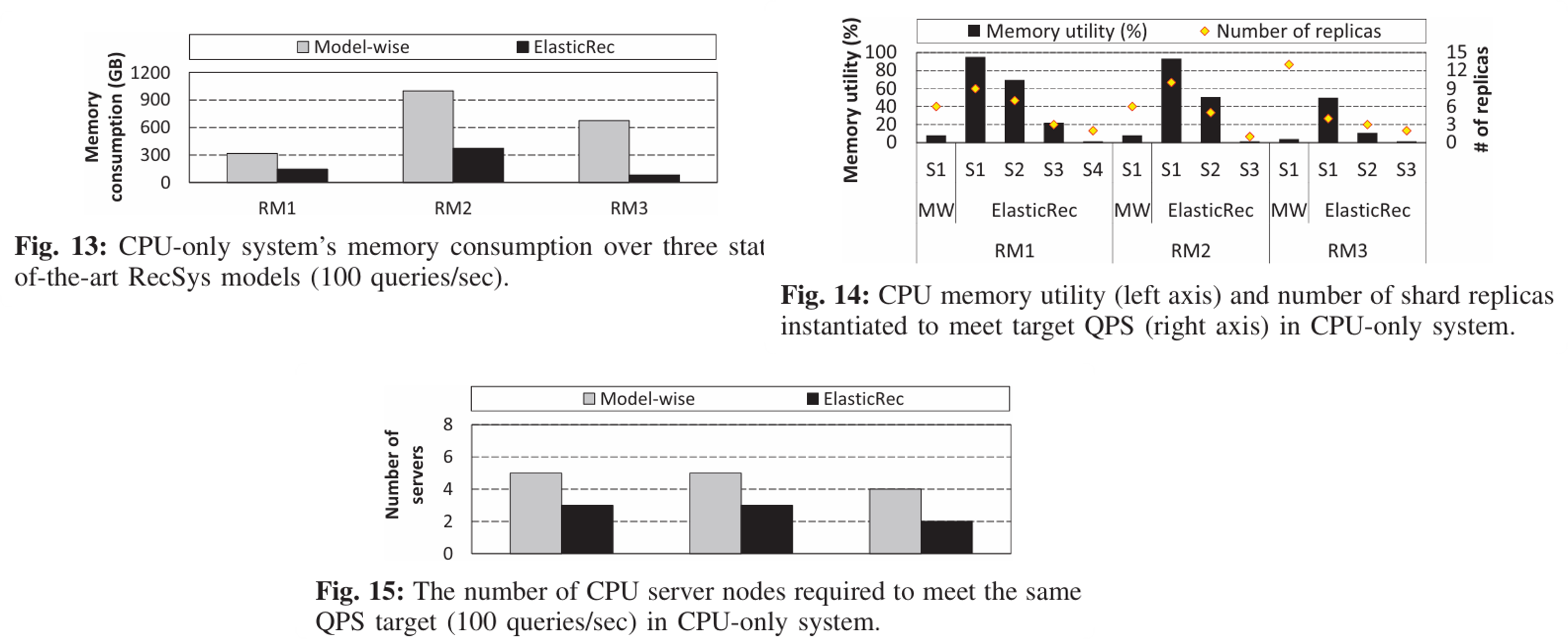
文章接下来在CPU-only环境下,比较了ElasticRec和Model-wise方法在三个推荐模型(RM1,RM2,RM3)的性能表现。以下实验都是在吞吐量为100QPS的下进行的
- Fig. 13 展示了内存消耗的对比
- Fig. 14
展示了内存利用率的对比,这里的内存利用率是作者自己定义的,表示当前shard在前1000个请求中被访问的embedding的比例,可以看出
Model-wise只有一个shard(S1),并且内存利用率很低,对整个shard扩容显得很不值;ElasticRec有4个shard,前3个内存利用率很高(高频shard),最后一个非常低。
- Fig. 15
展示了两种方法在吞吐量为100QPS所需要消耗的CPU服务器数量。这里我不太清楚是如何算出需要消耗的CPU服务器数量的(一般算的是虚拟CPU使用量?)
不同 RM 在 CPU-GPU
环境下的性能
在CPU-GPU环境下,ElasticRec将 MLP
模块设计为 GPU-centric 容器,将 Embedding Table 模块设计为只用 CPU
的容器;Model-wise
则将CPU和GPU都分配给一个容器。以下实验都是在吞吐量为100QPS的下进行的,实验效果如下
动态输入流量实验
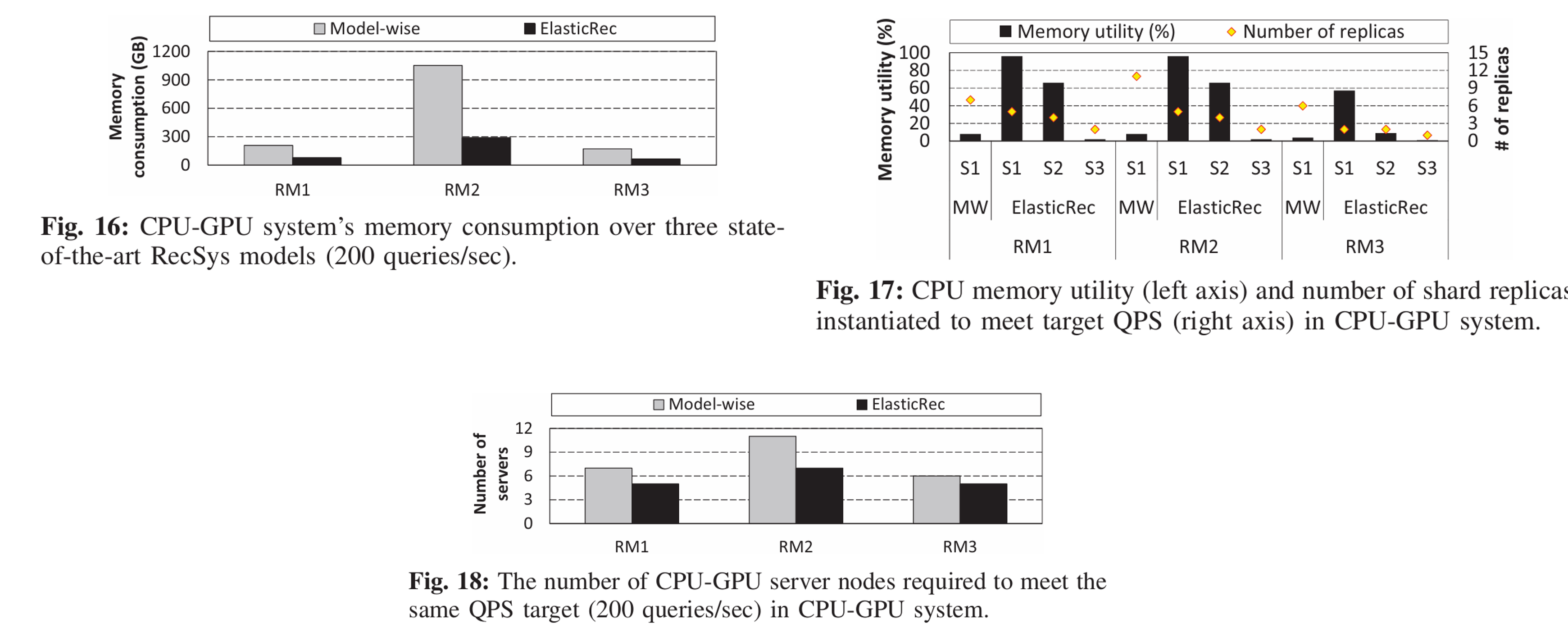
前几个实验都是在固定吞吐量(QPS=100)下进行的,这个实验动态调整流量大小,然后观察ElasticRec和Model-wise的吞吐量表现、资源消耗以及尾部延时。
流量大小先逐步增大,然后降到一个固定值
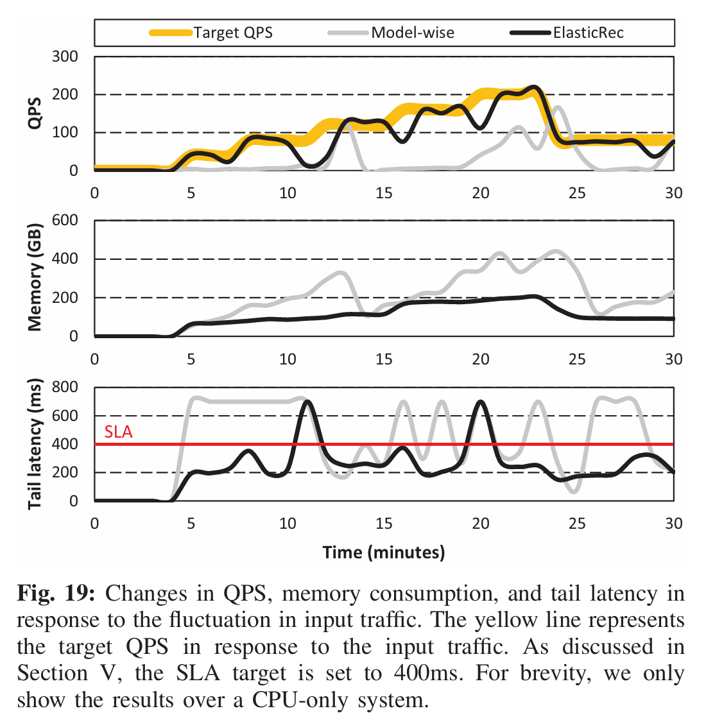
可以发现,ElasticRec的吞吐量、内存消耗以及SLA违背都低于对比方法
与 GPU Embedding Caches
的对比
GPU Embedding Caches
方法是之前的一个工作,原理是把Embedding Table的hot
embeddings存到GPU缓存中,能缓解CPU内存带宽压力(减少CPU与GPU的交互)
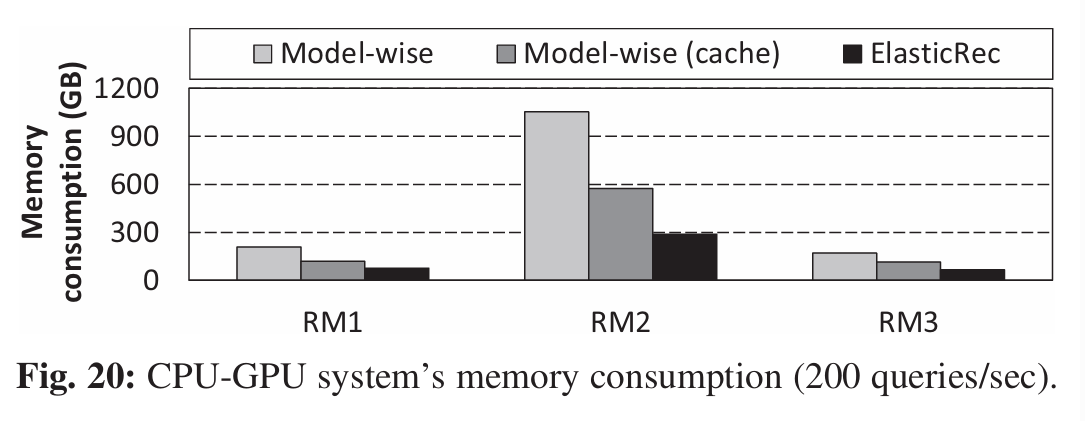
文章对比了 Model-wise、Model-wise (cache)
和 ElasticRec 在200 QPS
的内存消耗,ElasticRec的内存消耗仍然是最低的
这里我很好奇为什么不比较延时?ElasticRec延时应该比不过Model-wise (cache),毕竟CPU和GPU交互需要时间。