题目:On Optimizing Traffic Scheduling for Multi-replica Containerized Microservices
ICPP 2023
作者:中国科学技术大学,华为
摘要
基于容器的微服务系统部署已经变得越来越重要,为了应对高并发(high concurrency)和提升错误容忍度(fault tolerance),微服务系统通常会引入多个副本(replicas)。目前有两种类别的服务部署方法:
resource-friendly:将 pod 尽可能分散部署到不同机器上,目标是平均各机器的资源使用率。(e.g., Kubernetes,Docker Swarm,OpenShift)traffic localization:将流量(traffic)交互频繁的 pod放到同一台主机上,目标是减少跨主机流量导致的性能降级。(e.g., CA-WFD,Blender,NetMARKS)
这两种方法各有利弊:①
resource-friendly存在大量跨主机流量(cross-machine
traffic),可能会引发性能降级;②
traffic localization在多replicas情况下,由于机器资源不足,也会存在大量cross-machine
traffic。
文章提出了一种网络感知的流量调度(traffic scheduling)方法
OptTraffic,首先通过轻量级监控方法估计容器之间的流量大小,然后通过算法分配容器之间的流量比例(默认应该是负载均衡),目标是减少
cross-machine traffic,并尽可能平均各主机的资源利用率。
背景
基于容器的微服务
文章首先介绍了微服务是什么,这里就不进行赘述了。然后介绍了基于容器的微服务部署方法:
首先是传统的容器部署,代表为K8s,文章说是基于resource-friendly的,简而言之,就是只考虑容器的CPU和内存需求。这里我先查阅了K8s调度器
kube-scheduler 的说明,以下是文档的内容:
调度器执行步骤如下: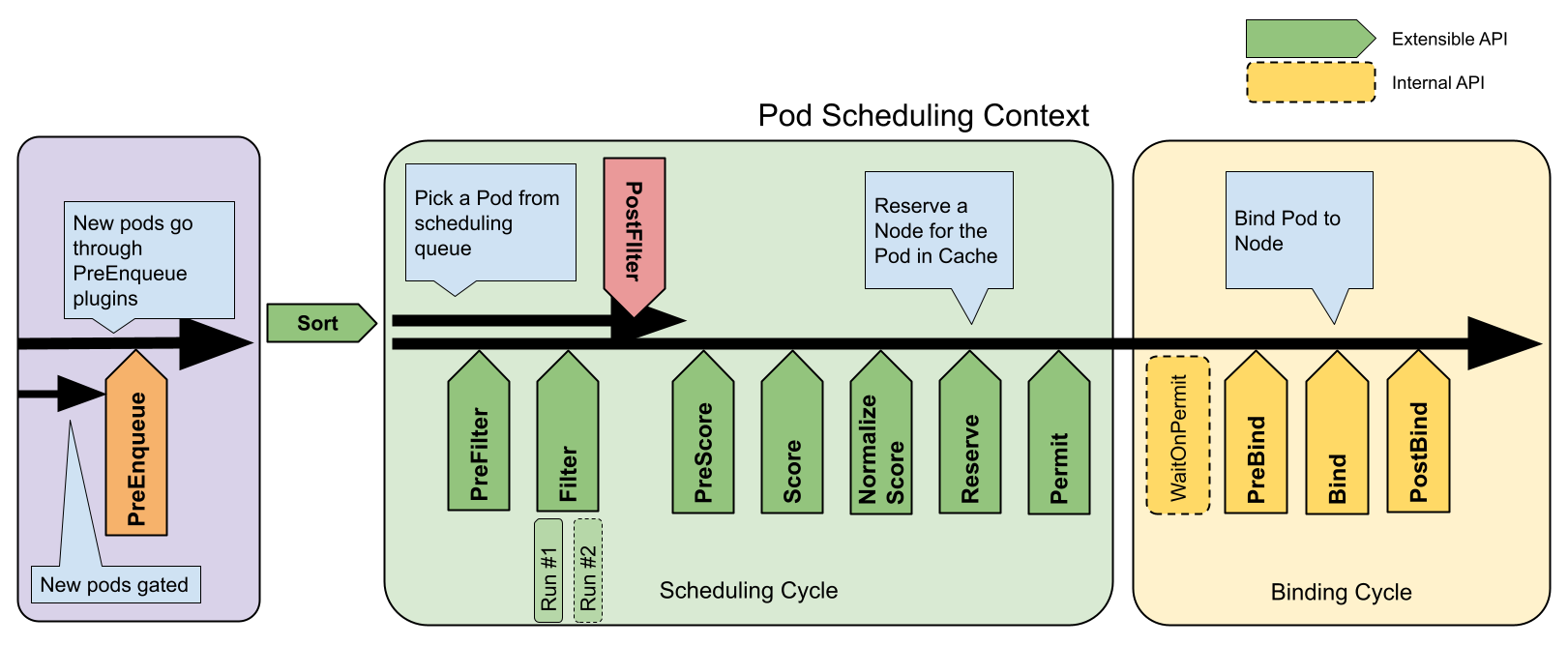
- 找出该 Pod 的所有 可选节点,这个过程称为过滤(filtering)
- 按照某种方式对每一个 可选节点 评分,这个过程称为打分(scoring)
- 选择评分最高的 可选节点
- 将最终选择结果通知 API Server,这个过程称为绑定(binding)
文章的重点在打分,假设全部节点皆可部署,则有如下打分策略:
SelectorSpreadPriority:将 Pod 分散到不同的节点,主要考虑同属于一个 Service、StatefulSet、Deployment的情况InterPodAffinityPriority:遍历 weightedPodAffinityTerm 并求和,找出结果最高的节点LeastRequestedPriority:已被消耗的资源最少的节点得分最高。如果节点上的 Pod 越多,被消耗的资源越多,则评分约低MostRequestedPriority:已被消耗的资源最多的节点得分最高。此策略会把 Pod 尽量集中到集群中的少数节点上RequestedToCapacityRatioPriority:按 requested / capacity 的百分比评分BalancedResourceAllocation:资源使用均衡的节点评分高NodePreferAvoidPodsPriority:根据节点的 annotation scheduler.alpha.kubernetes.io/preferAvoidPods 评分。可使用此 annotation (容忍度 Toleration 和 污点 Taint)标识哪些 Pod 不能够运行在同一个节点上NodeAffinityPriority:基于 PreferredDuringSchedulingIgnoredDuringExecution 指定的 node affinity 偏好评分。参考 将容器组调度到指定的节点TaintTolerationPriority: 根据节点上不可容忍的污点数评分ImageLocalityPriority:有限选择已经有该 Pod 所需容器镜像的节点ServiceSpreadingPriority:确保 Service 的所有 Pod 尽量分布在不同的节点上。CalculateAntiAffinityPriorityMap:anti-affinty,参考将容器组调度到指定的节点EqualPriorityMap:为每个节点指定相同的权重这些打分策略都有一定的权重,最终的分数计算如下:
经过查阅资料,默认开启的调度代码如下,可以看出,在所有节点都有对应镜像,没有亲和性和污点干扰的情况下,k8s其实偏向于
resource-friendly,即分布更加均匀,相关策略有BalancedAllocationName、LeastAllocatedName:
总的来说,K8s默认是
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Enabled: []schedulerapi.Plugin{
{Name: noderesources.BalancedAllocationName, Weight: 1},
{Name: imagelocality.Name, Weight: 1},
{Name: interpodaffinity.Name, Weight: 1},
{Name: noderesources.LeastAllocatedName, Weight: 1},
{Name: nodeaffinity.Name, Weight: 1},
{Name: nodepreferavoidpods.Name, Weight: 10000},
// Weight is doubled because:
// - This is a score coming from user preference.
// - It makes its signal comparable to NodeResourcesLeastAllocated.
{Name: podtopologyspread.Name, Weight: 2},
{Name: tainttoleration.Name, Weight: 1},
},
},resource-friendly的说法倒也没啥问题~~~
然后文章介绍了集中式部署,即以减少cross-machine
traffic为目标的traffic localization方法,这里进行了一个实证分析来论证cross-machine
traffic的影响,具体实验方法为:
将经典应用 socialNetwork 部署到2台主机,并用 sockperf 模拟两个主机之间的流量干扰,测量不同QPS下不同带宽的延时的P99分布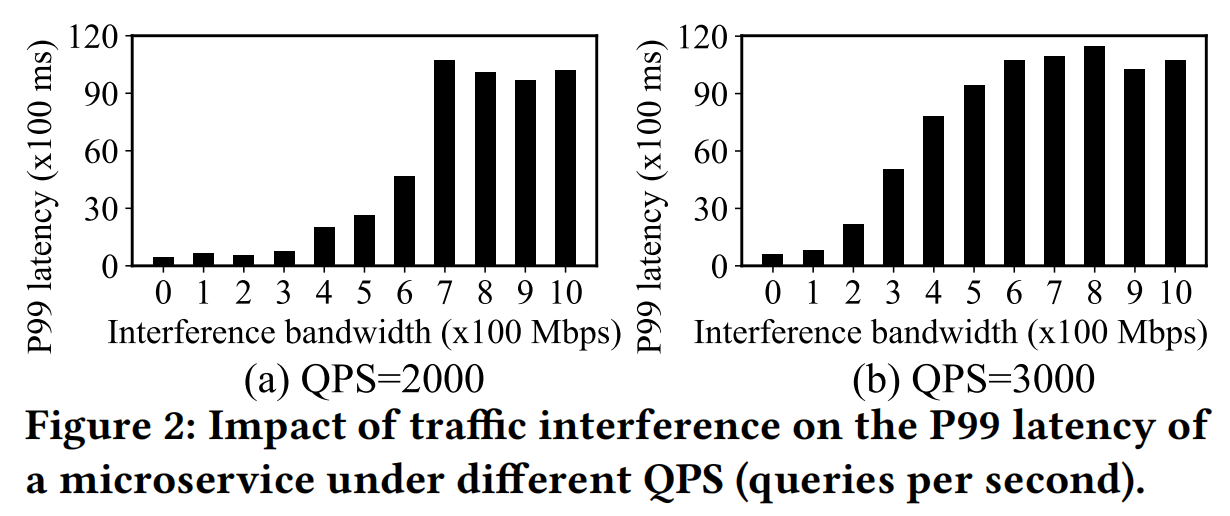
图中显示QPS增大时,同样带宽下的P99延时明显增大,所以cross-machine traffic受带宽限制,会影响延时。但这有没有可能是 POD 资源不够导致的(这里应该给 POD 设置足够充足的资源来消除影响)?
Traffic localization
及其局限
为了解决cross-machine traffic带来的性能降级问题,许多工作提出了
traffic localization 的部署方法,有两种实现方式:
- 将属于同一个application的所有容器部署到相同或邻近的主机
- 将流量交互密切的容器对(container pairs)调度到相同或邻近的主机
traffic localization 不仅可以减少 cross-machine traffic
带来的网络延迟(由传输路径和带宽大小决定),也可以减少对网络数据包操作(包的封装和解析)带来的计算开销。
为了验证
traffic localization对于节省网络流量和降低响应延时的作用,文章在两种部署方式上进行实验:
- 部署 socialNetwork 到 5 台主机上
- 部署 socialNetwork 到 1 台主机上(
traffic localization)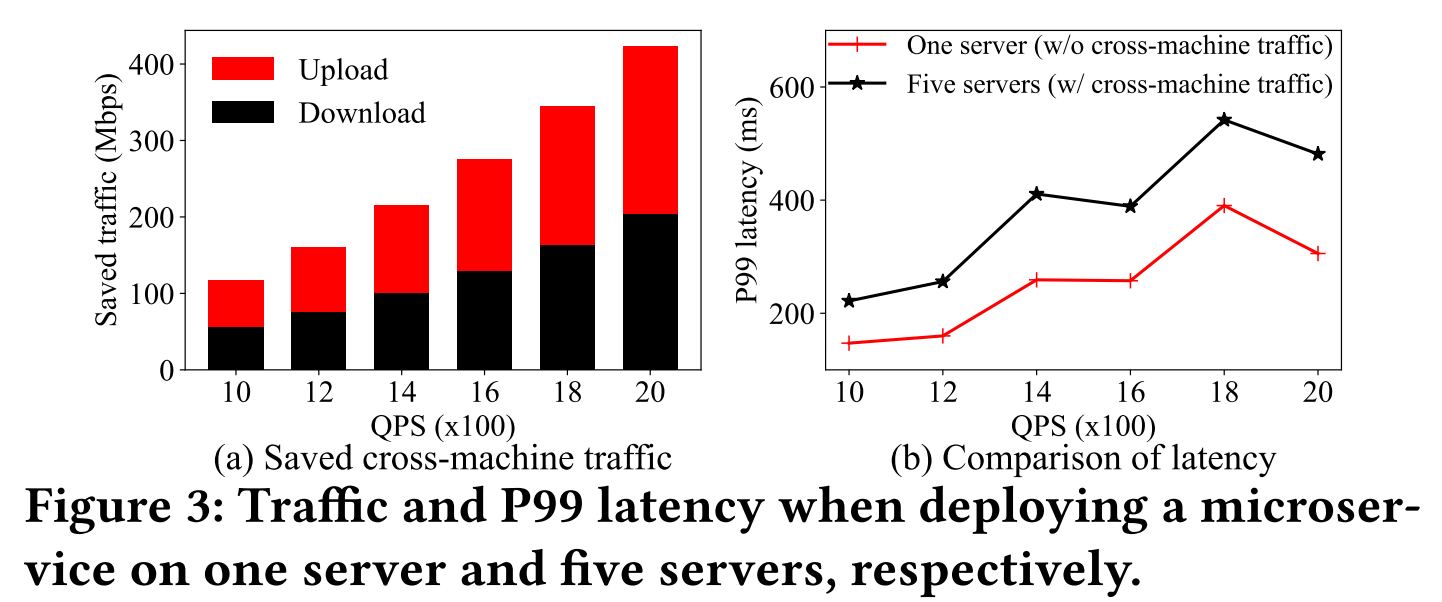
图(a)显示
traffic localization可以减少大量的cross-machine traffic。图(b)显示traffic localization可以大幅度减少响应延时
Limitation:traffic localization虽然能显著减少cross-machine
traffic来提升性能,但是通常很难完全将一个 application
的所有微服务都部署到一台主机上,原因在于微服务还会产生多个replicas,除此之外,监控容器之间的流量也会引入较大的CPU负载,traffic localization也会造成机器资源使用不均。具体如下:
(1)当 POD 分布在不同主机时。因为负载均衡,流量会均匀流向不同主机的POD,造成大量的cross-machine traffic
(2)高CPU负载。对容器间流量的监控一般需要抓取数据包,对数据包的封装和解析过程会造成高昂的CPU开销。比如socialNetwork有27个容器,消耗13个CPU核,而加上监控装置(e.g., iftop)会多消耗 1.4-2 个 CPU核【istio也存在这样的问题,甚至sidecar消耗更多】
(3)不均衡的资源使用。许多pod有着相同的资源需求,比如都是CPU密集型,将他们放置在一台主机上会造成资源使用不均衡,即CPU过载,但是内存利用率低。除此之外,将所有pod放在一台主机上会使得fault tolerance降低。
方法设计
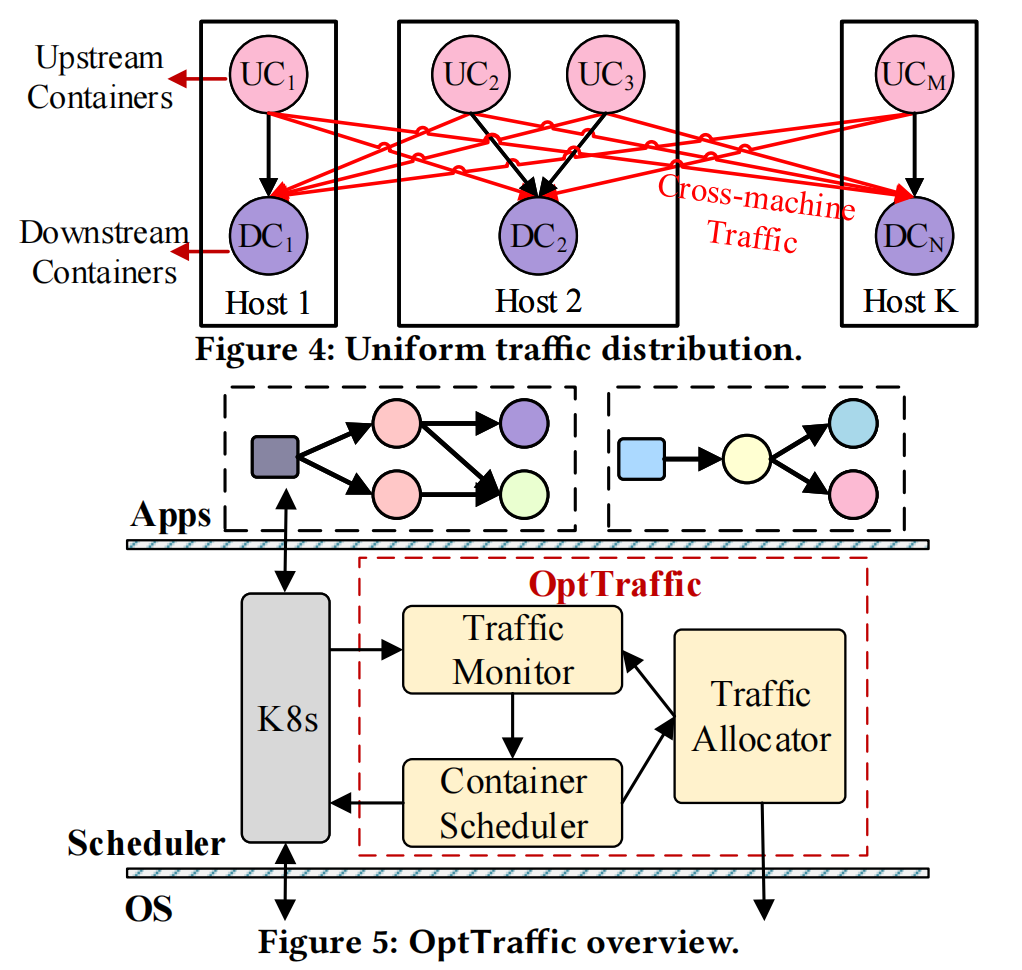
OptTraffic 的目标是最小化 cross-machine
traffic。整体架构如上图所示。包含三个组件:
Traffic Monitor。这个组件用轻量级的方式估计每个 container pair 之间的流量大小。做法为收集每个容器的 incoming 和 outgoing traffic,然后构建一个 traffic graph,最后通过简单的数学计算估计每个 container pair 之间的流量大小Traffic Allocator。流量调度模块,决定 upstream container 流向 每个 downstream container 的流量比例。具体策略为本地优先(local-first),以减少跨主机流量Container Scheduler。异步调整 container pairs 的部署,以实现机器之间的负载均衡。
Traffic Monitor
Traffic Monitor 有两个目的:①
识别频繁交互(heavy-traffic)的链路 ② 为链路调度进行优先级排序
现有两种方式进行容器间流量的监控:
- 在容器所在POD加一个sidecar,接管流量的转发和监控(e.g., istio)。
- 使用网络包嗅探工具在userspace进行解析(e.g., tcpdump and iftop)。
这两种方式都会造成高昂的CPU负载。文章还特别提到了在kernel space 工作的 eBPF,可以减少监控负载,但仍需要分析网络包,并且实现复杂。所以作者想用数学方法来减少监控带来的负载。
eBPF 避免用户态与内核态切换:传统上,像tcpdump这样的工具是在用户空间工作的,它们需要将网络数据包从内核空间复制到用户空间进行分析。这个过程涉及上下文切换和内存拷贝,带来了额外的CPU开销。而eBPF程序则可以在内核空间内部处理数据包,无需这种昂贵的数据传输。
Step 1: 监控容器流量。
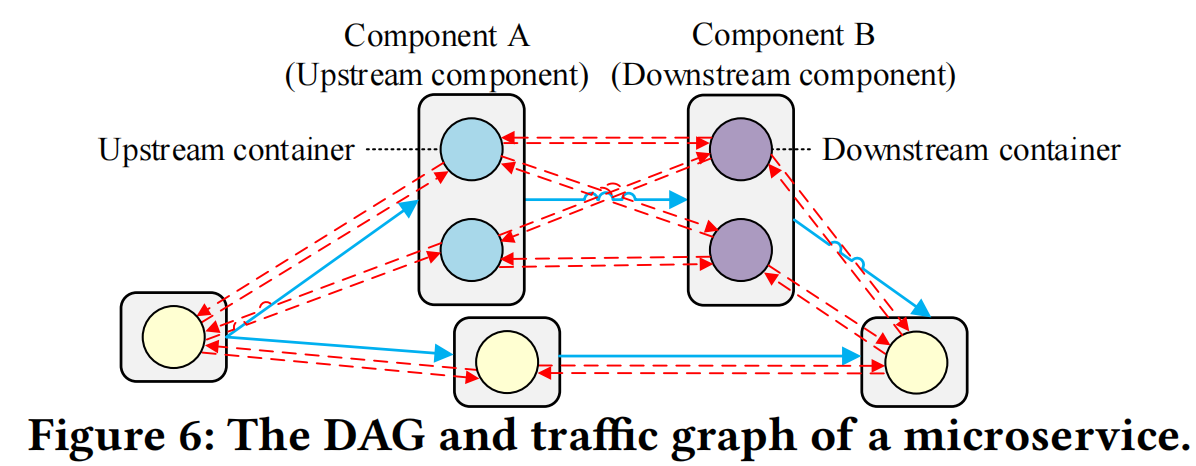
如 fig 6 所示,一个upstream container 可以与多个 downstream
container进行交互,OptTraffic首先使用 Prometheus
监控每个container接收和发送的traffic
Prometheus 只是一个收集工具,数据源来自于 操作系统记录的每个容器接收和发送的包的大小(这些数据已经保存在主机上,所以只需要周期性地获取就行,几乎没有监控成本),数据保存在 proc 文件系统中,经过查资料,应该用的是这两个指标:
- container_network_receive_bytes_total
- container_network_transmit_bytes_total
Step 2: 计算链路流量。链路流量(Link
Traffic)指的是特定的两个容器之间的流量大小,OptTraffic
直接使用数学方法计算得到,减少监控的负载(注意:上一步只能监控到每个容器的接收和发送的traffic大小,不能知道与特定容器之间的traffic大小)。计算步骤如下,从入度为
1 的节点 \(p\) (根节点)开始,先将与
\(p\) 相关的两条边赋值(即<\(p\),\(q\)>和<\(q\),\(p\)>),这两条边的值完全等于 \(p\) 的 send 和 receive 的 traffic 。然后将
\(p\) 相关的流量从 \(q\) 中减去,从图中删去 \(p\),重复如上过程,直到所有节点计算完毕。
- 构造微服务系统的 DAG。(可以通过通过配置文件、官方文档或者其他监控手段得到)
- 基于 DAG 构造 traffic graph。traffic graph有着和DAG相同的构造,唯一的不同是,traffic graph是双向边,代表 traffic 也可以从 downstream container 发往 upstream container (response)
- 基于 traffic graph 计算每个 link 的traffic大小,算法如下:

GraphMerge和BreakCycle两个函数用于解决图中存在环的情况。如下图所示,环有两种情况:
- upstream containers 来自不同微服务 (Fig. 7(b))
- upstream containers 来自同一个微服务的不同replicas (Fig. 7(c))
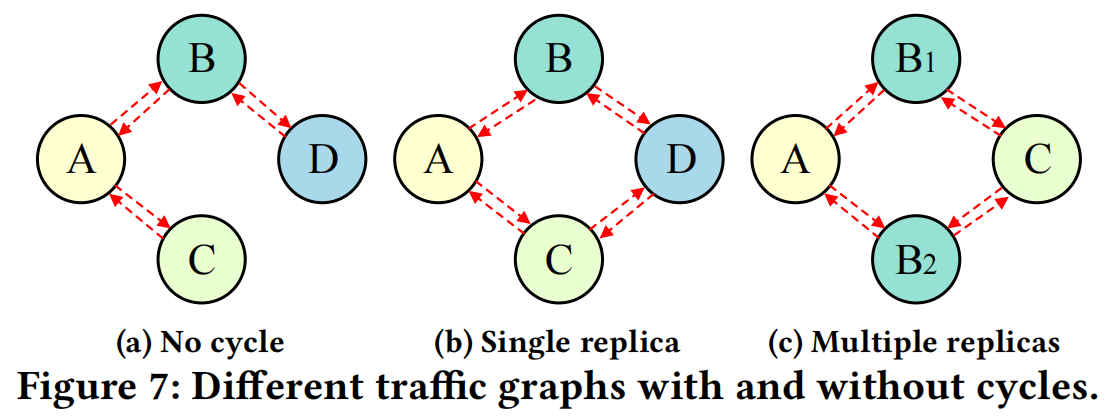
对于 case1,
BreakCycle函数首先选择环中 incoming 和 outgoing traffic 最少的 container 进行讨论,然后通过网络包嗅探工具监控这个 container 每条边 send 和 receive 的traffic。然后在相关 containers 中移除这个 container 的traffic,最后删除这个container,这样就可以破坏环。对于case2,
GraphMerge函数将属于同一个微服务的 replicas 进行合并,至于每个 replica 分得的 traffic,可以通过流量分配策略进行估算负载分析:从设计上看,
OptTrace确实轻量级,因为不需要监控每条 link 的 traffic,而每个 vertex 的 traffic 本身就被os记录下来了。即使有环,也只需要对一部分容器进行网络包嗅探分析,破环即可。算法复杂度为O(N),N为节点数量。
Traffic Allocation
这个模块是核心,决定了 upstream 微服务向某个 downstream 微服务的不同 replicas 发送 traffic 的比例。downstream 微服务的replicas可能部署在不同主机上,所以策略不再是简单的负载均衡
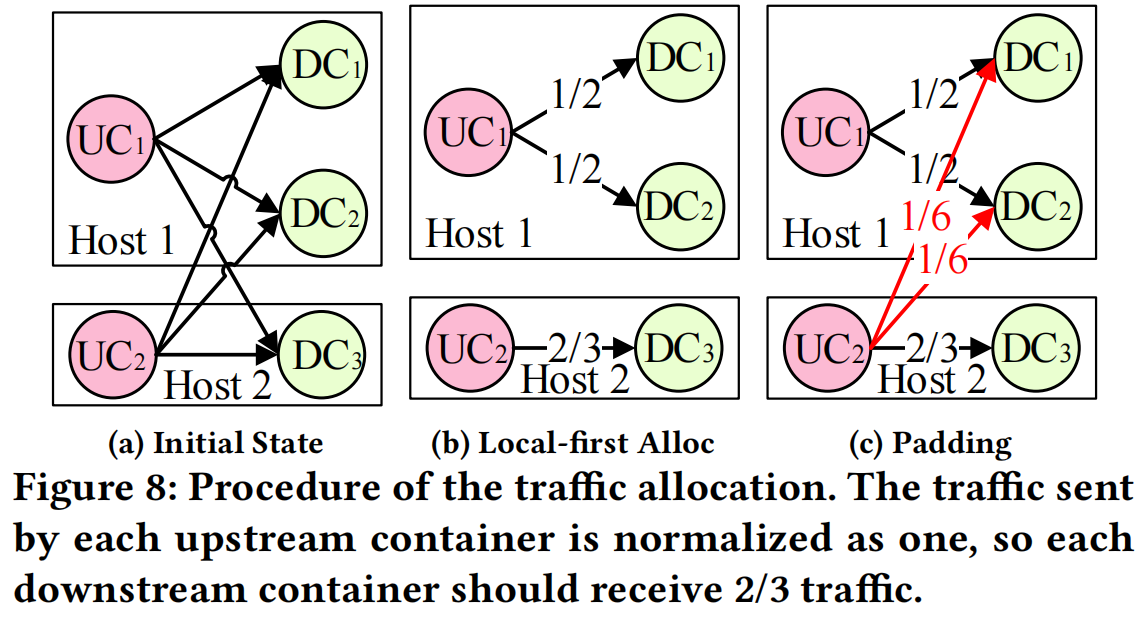
如上图所示,有2个 upstream containers 和 3个downstream containers,并部署在2台主机上。如果是按照负载均衡的原则,假设每个upstream container发送 1 traffic,则发往每个downstream container \(\frac{1}{3}\) traffic,每个downstream containers总共需要接收 \(\frac{2}{3}\) 的traffic。从Fig 8 (a)中看出,有 \(1=\frac{1}{3}+\frac{1}{3}+\frac{1}{3}\) (一半)的traffic是cross-machine的。
文章介绍了
Two-step allocation方法来进行 traffic 分配:
- 第一步,采用 local-first 原则,即traffic尽可能分配到同台主机的containers。假设机器 \(i\) 有 \(m_i\) 个upstream containers 和 \(n_i\) 个 downstream containers,则每个upstream container需要发送给每个downstream container比例为 \(min(\frac{m/n}{m_i}, \frac{1}{n_i})\)的traffic。这里的比例很简单也很有趣,每个downstream container接收到的traffic是 \(m_i\times min(\frac{m/n}{m_i}, \frac{1}{n_i})=min(m/n, m_i/n_i)\),第一个是全局负载均衡的traffic大小,第二个是单机上负载均衡的traffic大小。这里的原理是:使得低于负载均衡的traffic尽可能发往本机的container,但这个traffic尽量不高于全局负载均衡的值。所以 Fig 8 (b) 中 DC3 的 traffic 大小为 \(min(\frac{2}{3}, 1)=\frac{2}{3}\)
- 第二步,这一步叫
padding,即将第一步中剩余未分配的traffic导向其余downstream containers,这些traffic就是cross-machine traffic了。如 Fig 8 (c)所示。看了一下源代码,流量调度用的是iptable实现的,具体指令类似如下这样
以上是论文的核心,至于动态调度那一块,首先是没看懂,可能以后有时间再读读